
下面从一个例子入手:
利用正则表达式解析下面的XML/HTML标签:
<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>
希望自动格式化重写为:
composer: Wolfgang Amadeus Mozart
author: Samuel Beckett
city: London
一个代码是这样的形式:
#coding:utf-8
import re
s="""<composer>WolfgangAmadeus Mozart</composer>
<author>SamuelBeckett</author>
<city>London</city>"""
pattern1=re.compile("<\w+>") #匹配<>中任意的字符
pattern2=re.compile(">.+</") #匹配><中任意的字符
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
这个代码运行后结果是可以的。
下面我们修改下s的格式:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>"
pattern1=re.compile("<\w+>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile(">.+</") #匹配><中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
得到的答案如下所示:
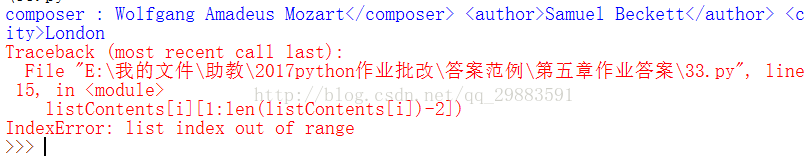
我们打印一下匹配到的两个结果看一下,修改代码如下:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>"
pattern1=re.compile("<\w+>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile(">.+</") #匹配><中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
print(listNames)
print(listContents)
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
显示结果如下:

从第一个箭头显示可以看出,这个处理是对的,那么看第二个箭头,这个匹配的结果显然是不对的了,那么是什么原因呢?
这是因为在正则中,‘*'、‘+'、‘?'这些是贪婪匹配,如用 a*,操作结果是尽可能多地匹配模式。所以当你试着匹配一对对称的定界符,如 HTML 标志中的尖括号。匹配单个 HTML 标志的模式不能正常工作,因为 .* 的本质是“贪婪”的 。在这种情况下,解决方案是使用不贪婪的限定符 *?、+?、?? 或 {m,n}?,尽可能匹配小的文本。
那么代码可以修改如下:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>"
pattern1=re.compile("<\w+?>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile(">.+?</") #匹配><中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
#输出的时候利用切片丢弃多余的符号,如:<>/
print(listNames[i][1:len(listNames[i])-1],":",
listContents[i][1:len(listContents[i])-2])
最后,用分组对代码的正则进行优化一下,如下:
#coding:utf-8
import re
s="<composer>Wolfgang Amadeus Mozart</composer><author>Samuel Beckett</author><city>London</city>"
pattern1=re.compile("<(\w+?)>") #匹配<>中任意的字符
# 此模式为非贪婪模式,所以s不是多行也可以匹配
pattern2=re.compile("<\w+?>(.+?)</\w+?>") #匹配<a>...</a>中任意的字符,问号必须加,"?"是非贪婪匹配
listNames=pattern1.findall(s) #获取所有满足正则表达式pattern1的字符串的列表
listContents=pattern2.findall(s) #获取所有满足正则表达式pattern2的字符串的列表
#由于xml是规范的,所以是一一对应(对于错误输入,暂时不考虑)
for i in range(len(listNames)):
print(listNames[i],":",
listContents[i])
这篇文章就介绍到这,大家可以多参考脚本之家以前发布的关于python 正则表达式的相关内容。











