1. SQL Server导入导出向导,这种方式是最方便的.
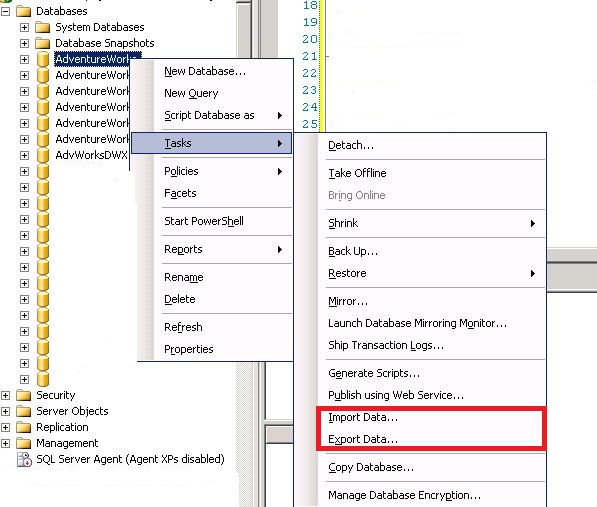
导入向导,微软提供了多种数据源驱动,包括SQL Server Native Cliant, OLE DB For Oracle,Flat File Source,Access,Excel,XML等,基本上可以满足系统开发的需求.
同样导出向导也有同样多的目的源驱动,可以把数据导入到不同的目的源.
对数据库管理人员来说这种方式简单容易操作,导入时SQL Server也会帮你建立相同结构的Table.
2. 用.NET的代码实现(比如有一个txt或是excel的档案,到读取到DB中)
2.1 最为常见的就是循环读取txt的内容,然后一条一条的塞入到Table中.这里不再赘述.
2.2 集合整体读取,使用OLEDB驱动.
代码如下:
string strOLEDBConnect = @"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=D:\1\;Extended Properties='text;HDR=Yes;FMT=Delimited'";
OleDbConnection conn = new OleDbConnection(strOLEDBConnect);
conn.Open();
SQLstmt = "select * from 1.txt";//读取.txt中的数据
DataTable dt=new DataTable();
OleDbDataAdapter da = new OleDbDataAdapter(SQLstmt, conn);
da.Fill(dt);//在DataSet的指定范围中添加或刷新行以匹配使用DataSet、DataTable 和IDataReader 名称的数据源中的行。
if(dt.Rows.Count>0)
foreach(DataRow dr in dt.Rows)
{
SQLstmt = "insert into MyTable values('" + dr..."
3.BCP,可以用作大容量的数据导入导出,也可以配合xp_cmdshell来使用.
语法:
BCP语法
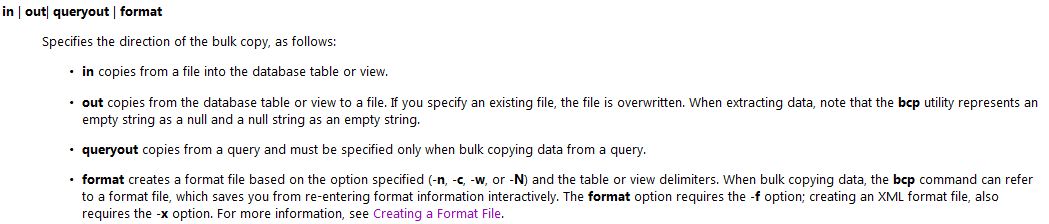
bcp {[[database_name.][schema].]{table_name | view_name} | "query"}
{in | out | queryout | format} data_file
[-mmax_errors] [-fformat_file] [-x] [-eerr_file]
[-Ffirst_row] [-Llast_row] [-bbatch_size]
[-ddatabase_name] [-n] [-c] [-N] [-w] [-V (70 | 80 | 90 )]
[-q] [-C { ACP | OEM | RAW | code_page } ] [-tfield_term]
[-rrow_term] [-iinput_file] [-ooutput_file] [-apacket_size]
[-S [server_name[\instance_name]]] [-Ulogin_id] [-Ppassword]
[-T] [-v] [-R] [-k] [-E] [-h"hint [,...n]"]
请注意数据导入导出的方向参数:in,out,queryout
如:
如:

4.BULK INSERT. T-SQL的命令,允许直接导入数据
语法:
BULK INSERT
[ database_name. [ schema_name ] . | schema_name. ] [ table_name | view_name ]
FROM 'data_file'
[ WITH
(
[ [ , ] BATCHSIZE =batch_size ]
[ [ , ] CHECK_CONSTRAINTS ]
[ [ , ] CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ [ , ] DATAFILETYPE =
{ 'char' | 'native'| 'widechar' | 'widenative' } ]
[ [ , ] FIELDTERMINATOR = 'field_terminator' ]
[ [ , ] FIRSTROW = first_row ]
[ [ , ] FIRE_TRIGGERS ]
[ [ , ] FORMATFILE ='format_file_path' ]
[ [ , ] KEEPIDENTITY ]
[ [ , ] KEEPNULLS ]
[ [ , ] KILOBYTES_PER_BATCH =kilobytes_per_batch ]
[ [ , ] LASTROW =last_row ]
[ [ , ] MAXERRORS =max_errors ]
[ [ , ] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ]
[ [ , ] ROWS_PER_BATCH =rows_per_batch ]
[ [ , ] ROWTERMINATOR ='row_terminator' ]
[ [ , ] TABLOCK ]
[ [ , ] ERRORFILE ='file_name' ]
)]
重要参数:
FIELDTERMINATOR,字段分隔符
FIRSTROW:第一个数据行
ROWTERMINATOR:行终结符
如:
BULK INSERT dbo.ImportTest
FROM 'C:\ImportData.txt'
WITH ( FIELDTERMINATOR =',', FIRSTROW = 2 )
5. OPENROWSET也是T-SQL的命令,包含有DB连接的信息和其它导入方法不同的是,OPENROWSET可以作为一个目标表参与INSERT,UPDATE,DELETE操作.
语法:
OPENROWSET
( { 'provider_name', { 'datasource';'user_id';'password'
| 'provider_string' }
, { [ catalog. ] [ schema. ] object
| 'query'
}
| BULK 'data_file',
{ FORMATFILE ='format_file_path' [ <bulk_options> ]
| SINGLE_BLOB | SINGLE_CLOB | SINGLE_NCLOB }
} )<bulk_options> ::=
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ERRORFILE ='file_name' ]
[ , FIRSTROW = first_row ]
[ , LASTROW = last_row ]
[ , MAXERRORS = maximum_errors ]
[ , ROWS_PER_BATCH =rows_per_batch ]
如:
INSERT INTO dbo.ImportTest
SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\ImportData.xls', 'SELECT * FROM [Sheet1$]' WHERE A1 IS NOT NULL)
6.OPENDATASOURCE
语法:
OPENDATASOURCE ( provider_name,init_string )
如:
INSERT INTO dbo.ImportTest
SELECT * FROM OPENDATASOURCE('Microsoft.Jet.OLEDB.4.0',
'Data Source=C:\ImportData.xls;Extended Properties=Excel 8.0')...[Sheet1$]
7.OPENQUERY.是在linked server的基础上执行的查询.所以执行之前必须先建立好link server.OPENQUERY的结果集可以作为一个table参与DML的操作.
语法:
OPENQUERY (linked_server ,'query')
如:
EXEC sp_addlinkedserver 'ImportData',
'Jet 4.0', 'Microsoft.Jet.OLEDB.4.0',
'C:\ImportData.xls',
NULL,
'Excel 8.0'
GO
INSERT INTO dbo.ImportTest
SELECT *
FROM OPENQUERY(ImportData, 'SELECT * FROM [Sheet1$]')
以上只是简单总结的一些DB数据导入导出的方法及其一些简单的实例,希望对你实践中会有所帮助.












