
开始
突发奇想, 想看下高考成绩的分布, 如果把每个省市的成绩划线成0-100 分会怎么样,简单的来说, 认为最高分的考了100分,最低分考了0分, 计算一下各个分数段的人数就好了,
顺便可以用这个数据看每个省市的一本线划分比率,还有其他相关的数据,
看起来还是比较简单的, 动手试试
数据收集
网上找了一下, 每年的高考人数, 现在已经超过千万人高考了,河南更是超过了100万,
数据来源:新浪教育 https://edu.sina.cn/zt_d/gkbm
| 省/市 | 2020年 | 2019年 | 2018年 | 2017年 | 2016年 | 2015年 | 2014年 | 2013年 | 2012年 |
|---|---|---|---|---|---|---|---|---|---|
| 全国 | 1071万↑ | 1031万↑ | 975万↑ | 940万 | 940万↓ | 942万↑ | 939万↑ | 912万↓ | 915万↓ |
| 河南 | 115.8万↑ | 100万+↑ | 98.3万↑ | 86.3万↑ | 82万↑ | 77.2万↑ | 72.4万↓ | 71.63万↓ | 80.5万↑ |
| 广东 | 78.8万↑ | 76.8万↑ | 75.8万↑ | 75.7万↑ | 73.3万↓ | 75.4万↓ | 75.6万↑ | 72.7万↑ | 69.2万↑ |
| 四川 | 67万↑ | 65万↑ | 62万↑ | 58.3万↑ | 57.13万 | 超57万 | 57.17万↑ | 54万↑ | 53.8万↑ |
| 河北 | 62.48万↑ | 55.96万↑ | 48.6万↑ | 43.6万↑ | 42.31万↑ | 40.48万↓ | 41.82万↓ | 44.98万↓ | 45.93万↓ |
| 安徽 | 52.38万↑ | 51.3万↑ | 49.9万 | 49.9万↓ | 50.99万↓ | 54.6万↑ | 52.7万↑ | 51.1万↑ | 50.6万↓ |
| 湖南 | 53.7万↑ | 50万↑ | 45.2万↑ | 41.1万↑ | 40.16万↑ | 38.99万↑ | 37.8万↑ | 37.3万↑ | 35.2万↓ |
| 山东 | 53万↓ | 55.99万↑ | 59.2万↑ | 58.3万↓ | 60.2万↑ | 69.61万↑ | 55.8万↑ | 50万↓ | 51万↓ |
| 广西 | 50.7万↑ | 46万↑ | 40万↑ | 36.5万↑ | 33万余↑ | 近31万↓ | 31.5万↑ | 29.8万↑ | 28.5万↓ |
| 贵州 | 47万↑ | 45.8万↑ | 44.1万↑ | 41.2万↑ | 37.38万↑ | 33.05万↑ | 29.27万↑ | 24.78万↓ | 24.8万↑ |
| 江西 | 38.94万↓ | 42.1万↑ | 38万↑ | 36.5万↑ | 36.06万↑ | 35.46万↑ | 32.59万↑ | 27.43万↑ | 26.9万↓ |
| 湖北 | 39.48万↑ | 38.4万↑ | 37.4万↑ | 36.2万↑ | 36.14万↓ | 36.84万↓ | 40.27万↓ | 43.8万↓ | 45.7万↓ |
| 江苏 | 34.89万↑ | 33.9万↑ | 33万 | 33万↓ | 36.04万↓ | 39.29万↓ | 42.57万↓ | 45.1万↓ | 47.4万↓ |
| 山西 | 32.6万↑ | 31.4万↑ | 30.5万↓ | 31.7万↓ | 33.9万↓ | 34.22万↑ | 34.16万↓ | 35.8万↓ | 36.1万↑ |
| 云南 | 34.3万↑ | 32.6万↑ | 30万↑ | 29.3万↑ | 28万↑ | 27.21万↑ | 25.59万↑ | 23.6万↑ | 21万↓ |
| 陕西 | 32.23万↓ | 32.59万↑ | 31.9万 | 31.9万↓ | 32.8万余↓ | 34.4万↓ | 35.3万↓ | 36.65万↓ | 37.53万↓ |
| 浙江 | 32.57万↑ | 31.5万↑ | 30.6万↑ | 29.1万↓ | 30.74万↓ | 31.79万↑ | 30.86万↓ | 31.3万↓ | 31.6万↑ |
| 重庆 | 28.3万↑ | 26.4万↑ | 25万↑ | 24.7万↓ | 24.88万↓ | 25.54万↑ | 25.06万↑ | 23.5万↑ | 23万↑ |
| 辽宁 | 24.4万↑ | 18.5万↓ | 20.8万↓ | 21.82万↓ | 22.51万↓ | 23.9万↓ | 25.4万↓ | 25.6万↑ | |
| 甘肃 | 26.31万↑ | 21.8万↓ | 27.3万↓ | 28.5万↓ | 29.6万余↓ | 30.38万↑ | 29.7万↑ | 28.3万↓ | 29.6↓ |
| 黑龙江 | 21.1万↑ | 20.6万↑ | 16.9万↓ | 18.8万↓ | 19.7万↓ | 19.8万↓ | 20.4万↓ | 20.8万↓ | 21万↑ |
| 福建 | 20.26万↓ | 20.78万↑ | 20万↑ | 18.8万↑ | 17.5万↓ | 18.93万↓ | 25.5万 | 25.5万↑ | 25万↓ |
| 内蒙古 | 197901↑ | 19.5万↓ | 19.8万↓ | 20.11万↓ | 18.4万↓ | 18.8万↓ | 19.3万↑ | 18.95万↓ | |
| 新疆 | 22.93万↑ | 20.7万↑ | 18.4万↑ | 16.61万↑ | 16.05万↓ | 16.26万↑ | 15.87万↑ | 15.47万↑ | |
| 吉林 | 15万余↑ | 15万↑ | 14.3万↓ | 14.85万↓ | 13.76万↓ | 16.02万↑ | 15.9万↓ | 16.2万↓ | |
| 宁夏 | 60298↓ | 7.17万↑ | 6.9万 | 6.9万 | 6.9万↑ | 6.7万↑ | 6.4万↑ | 5.87万↓ | 6.02万↑ |
| 海南 | 57336↓ | 5.9万↑ | 5.8万↑ | 5.7万↓ | 6.04万↓ | 6.2万↑ | 6.1万↑ | 5.6万↑ | 5.5万↑ |
| 北京 | 49225↓ | 5.9万↓ | 6.3万↑ | 6万↓ | 6.12万↓ | 6.8万↓ | 7.05万↓ | 7.27万↓ | 7.3万↓ |
| 青海 | 46620↑ | 44313↑ | 4.2万↓ | 4.6万↑ | 4.5万↑ | 4.2万↑ | 3.97万↓ | 4.06万↑ | 3.8万↓ |
| 天津 | 56258↑ | 5.5万 | 5.5万↓ | 5.7万↓ | 约6万↓ | 6.1万↓ | 约6万 | 6.3万↓ | 6.4万↓ |
| 上海 | 5万 | 5万+ | 约5.1万 | 5.1万↓ | 5.2万↓ | 5.3万↓ | 5.5万↓ | ||
| 西藏 | 32973↑ | 2.5万↓ | 2.8万↑ | 2.4万↑ | 2.1万↑ | 1.96万↑ | 1.89万↓ | 1.9万↑ |
这个表的数据是统计的全国各个省市(除港澳台)之外的数据, 各个省市在出成绩之后会出各自的一分一段表, 统计每一分的成绩的人数, 我们以这个数据为准, 由于个人还是没有太多精力去收集数据的,网上找到了 高考100-一分一段表
这个网站, 给出了各个省市的一分一段表, excel 版本, 稍微检查了一下, 数据应该是对的,我就暂时以这个数据为准,
数据太多, 我暂时只做 35万 以上人的省市,只有11个省市,加上 北京上海两个城市的数据,
其中北京上海不分科,山东是选择一门考试进行考核, 所以 一共23个数据表,后续的话,我尽量将数据也一并上传了
数据整理
上面也提到了北京上海山东的分科比较特殊, 我们就按文理一起算,每个省都是给出最高分及以上的数据, 然后给出100分及以下的数据,但是不是每个省都是100分以下,所以还要特殊考虑,
不同高考政策与分类
山东的高考政策具体不清楚, 但是似乎是考生是在6门副科中任选3门,从一图了解山东高考改革要点
这里查到的

我们就不做分科了, 直接看山东的全体成绩即可。
不同统计方式
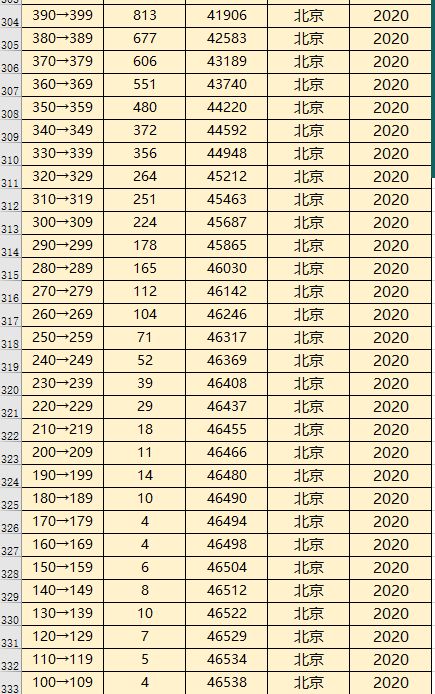
北京的人数更少,在400分以下每10分段给出人数,我们为了便于方便 默认每个分数平均人数, 比如 390-399分段的人有813人,我们认为每个分段都有81.3人,暂时这么处理。
不同省市对于最高分数的表示都是 最高分数及以上, 但是对于最低分数的处理就不太一样了, 这里不做评价
比如很多省市是合并在一起 100分以下总计, 有些则只是100分的成绩, 100分以下的成绩是没有给出的,这里最后处理的时候, 我们把0分的人都删除了, 只计算1-100 的人,反正不影响整个曲线

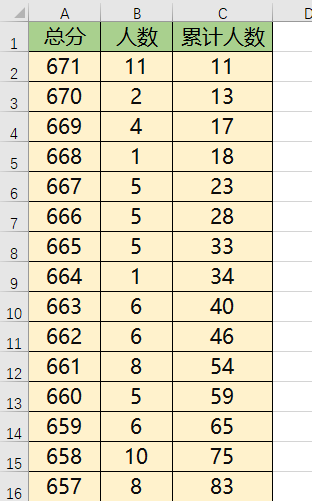
最终我们整理得到数据表, 每个Sheet 表示一个省市的文理科目,然后最上面一行数据分别对应 总分,人数, 累计人数,
数据处理
数据处理思路
这里为了方便 顺手用 Python 来做的, 使用的 pandas 读取的 excel 文件,
我们统计所有的数据的目标就是 将成绩化为 0-100分
那么
\[变换后分数 = \frac{当前分数-最低分}{最高分-最低分} \times 100\]
对于每个省的成绩将其调整到 [0,100], 这里使用的是 四舍五入, 导致实际在计算过程中的数据会重叠,比如相邻的两个成绩一个舍去,一个入上,在统一分数,导致数据噪声较大, 这是使用 一维的中值滤波平滑一下数据就好了,
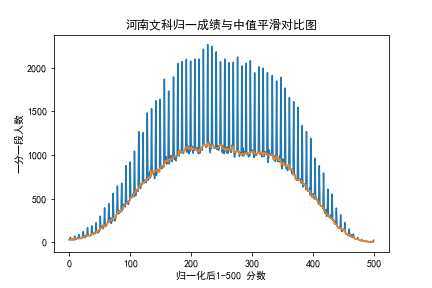
以河南文科为例, 我们直接绘制归一化之后的成绩并进行中值滤波之后对比,
(图为测试过程中归一化到500分的图像,不影响理解)
各省市分数分布
我们在之前已经整理得到的数据, 然后我们 就要动手做了,
# 整理数据,将各省市的成绩归一到100分之后的分布比率
# 引入 pandas
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import scipy.signal as ss
# 设定中文字体
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 设定图像尺寸 与分辨率
plt.rcParams['figure.figsize'] = (8.0, 4.0) # 设置figure_size尺寸
plt.rcParams['image.interpolation'] = 'nearest' # 设置 interpolation style
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300 #分辨率
# 将成绩统一到 [0,] 区间
MAX_SCORE = 100
MIN_SCORE = 0
data_file = 'Data/data.xlsx'
res_file = 'Data/res-'+str(MAX_SCORE-MIN_SCORE)+'.xlsx'
# 读取excel , 获取所有表单名字
excel_info = pd.ExcelFile(data_file)
all_data = {}
all_data_ratio = {}
# 获取表中的每一个数据文件 并将数据归一化到 0-500
for index in range(len(excel_info.sheet_names)):
# 读取每一个表单
cur_sheetname = excel_info.sheet_names[index]
df_sheet = pd.read_excel(data_file, sheet_name=cur_sheetname)
# 获取每一个表中的 总分数 和对应分数的人数
scores = df_sheet[df_sheet.columns.values[0]]
nums = df_sheet[df_sheet.columns.values[1]]
# 数据 对应 每个分数的人数 表
ROWS = MAX_SCORE - MIN_SCORE + 1
trans_scores_nums = [0] * ROWS
rows = len(scores)
cur_max_score = scores[0]
cur_min_score = scores[rows - 1]
cur_index = 0;
for s in scores:
# 计算 变换之后的分数 四舍五入
trans_score = (int)(round((s - cur_min_score) / (cur_max_score - cur_min_score) * (MAX_SCORE - MIN_SCORE)))
# 在计算分数的位置上 加上对应分数的人数
trans_scores_nums[trans_score - 1] += nums[cur_index];
cur_index += 1
# 数据稍微处理一下, 做简单的平滑处理, 去除最低分数据
except0data = [0] * (ROWS - 1)
for i in range(ROWS - 1):
except0data[i] = trans_scores_nums[i + 1];
# 中值滤波去除噪点
smooth_trans = ss.medfilt(except0data, 7)
# 将数据转换成比例, 更具有一般性
sum = 0
smooth_trans_ratio = [0] * (ROWS - 1)
for i in range(ROWS - 1):
sum += smooth_trans[i]
for i in range(ROWS - 1):
smooth_trans_ratio[i] = smooth_trans[i] / sum
all_data[cur_sheetname] = smooth_trans
all_data_ratio[cur_sheetname] = smooth_trans_ratio
print('正在进行 {0}/{1}, 表名:{2}'.format(index + 1, len(excel_info.sheet_names), cur_sheetname))
# plt.plot(smooth_trans2)
# write_data = pd.DataFrame(all_data)
# write_data.to_excel(res_file,sheet_name='res')
write_data_ratio = pd.DataFrame(all_data_ratio)
write_data_ratio.to_excel(res_file, sheet_name='ratio')
print('已经完成,存储文件:{0}'.format(res_file))
我们在这个程序里面主要是 将数据提取出来, 计算成 100分制之后,重新存入 excel 表中,其中人数部分换成了各省市的人数比率,也方便查阅后续的数据
( 因为我感觉 plt 绘制图像不好看,这边使用了MATLAB 进行图像的绘制过程)
% 将 原始数据绘制出来 并计算平均值和中值
% 读取 excel 数据 获取名称以及各列名称
data_file = 'Data/res-100.xlsx';
res_ratio = xlsread(data_file,1,'B2:X501');
res_name = {'河南文科', '河南理科', '北京', '上海', '河北文科', '河北理科', '山东', '广东文科' '广东理科' '湖北文科', '湖北理科', '湖南文科', '湖南理科', '四川文科', '四川理科', '安徽文科', '安徽理科', '广西文科', '广西理科', '贵州文科', '贵州理科', '江西文科', '江西理科'};
figure()
hold on
[rows,cols] = size(res_ratio);
avg = zeros(cols,1);
media =zeros(cols,1);
for i=1:cols
% 绘制百分比率图
plot(res_ratio(:,i)*100);
% 计算平均值 中值
media_l = 0.5;
media_find_flg = 0;
for j = 1:rows
avg(i) = avg(i) + j*res_ratio(j,i);
% 统计比率超过一半的 数之后就是中值 找到后就不更新了
if(media_find_flg ==0)
if(media_l >0)
media_l = media_l - res_ratio(j,i);
else
media(i) = j;
media_find_flg = 1;
end
end
end
end
legend(res_name);
% 创建 xlabel
xlabel({'归一化到100分后成绩'});
% 创建 title
title({'各省市归一化成绩分布比率'});
% 创建 ylabel
ylabel({'单位成绩分布比率'});
最终我们得到了这样的一副图, 细节部分比较多,且数据噪声较大,但是数据的整体趋势大概明白了,噪声较大的黄色的线是北京的,暂时不做过多分析
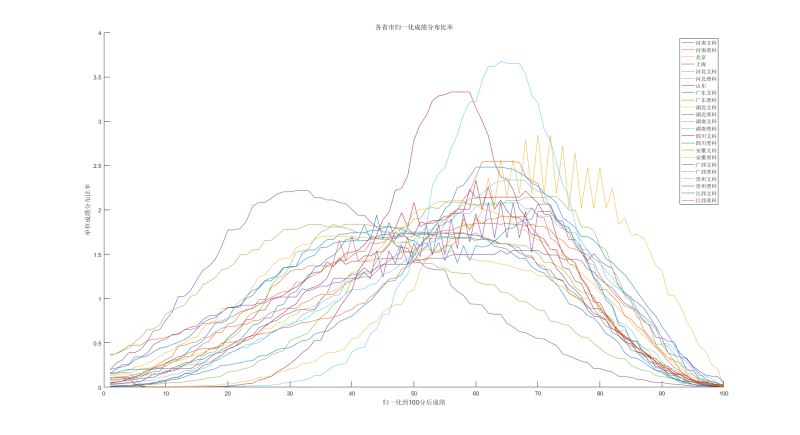
各省市分数平均值与中值
我们这里的计算平均值就是 每分段人数乘以该分段的比例,最终得到的结果,
然后, 中值这里简单除暴, 找到中间比率所在的区间就好了, 代码没有去过多处理, 能跑出来结果就好
| **** | 平均数 | 中数 | 众数 |
|---|---|---|---|
| 河南文科 | 49.48792233 | 50 | 46 |
| 河南理科 | 54.58292813 | 58 | 65 |
| 北京 | 68.04792125 | 70 | 70 |
| 上海 | 57.56537197 | 60 | 62 |
| 河北文科 | 51.23109382 | 52 | 37 |
| 河北理科 | 58.00918618 | 61 | 66 |
| 山东 | 53.14176529 | 56 | 60 |
| 广东文科 | 47.7185653 | 49 | 52 |
| 广东理科 | 48.64707915 | 51 | 55 |
| 湖北文科 | 48.50952865 | 49 | 37 |
| 湖北理科 | 51.9093088 | 55 | 64 |
| 湖南文科 | 60.26081026 | 62 | 72 |
| 湖南理科 | 59.09632919 | 62 | 65 |
| 四川文科 | 54.82215427 | 57 | 59 |
| 四川理科 | 61.59698771 | 64 | 60 |
| 安徽文科 | 51.95829486 | 55 | 69 |
| 安徽理科 | 54.62690506 | 57 | 56 |
| 广西文科 | 37.84799656 | 37 | 31 |
| 广西理科 | 41.46558284 | 41 | 33 |
| 贵州文科 | 63.48516406 | 65 | 64 |
| 贵州理科 | 57.96584346 | 58 | 56 |
| 江西文科 | 53.35740184 | 55 | 71 |
| 江西理科 | 56.85982591 | 61 | 62 |
数据简单分析
我们在上一章节给出了一张图, matlab 绘制的图的颜色比较接近, 建议下载原图观看,给出了分布图,
我们把数据最为特殊的几条线单独绘制一下,
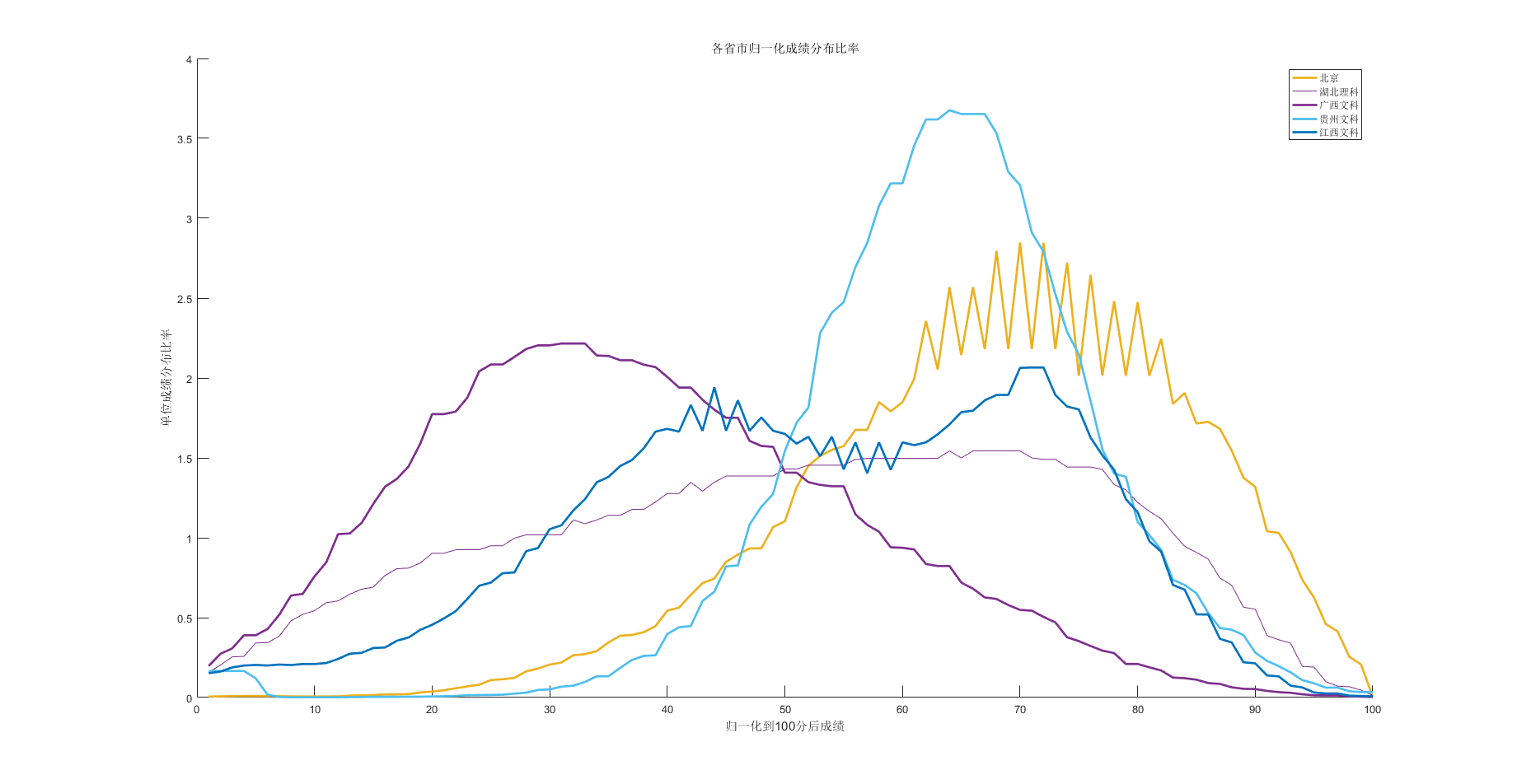
其实这些形态是有独特的意义的,理论上的曲线是正太分布的,但是由于各种原因,我们以实际曲线为主,
就总体而言, 各个省市的成绩的峰值(众数)也主页也分为两个部分,部分省市的峰值在40分左右,主要包括河南文科,河北文科,湖北文科,广西文科,广西理科
剩下的分数的众数都集中在60分多一点的位置,
emmm, 就这么多了, 再多的分析也没有太多用, 毕竟北京NB
剩下的部分就是 高考本科上线率这种数据了, 但是各省对于本科的分数线真是不同

我给出的数据是我在各地高考历年分数线(批次线) 这个网页上能看到2020 年各省高考批次线, 一般的省市都是划分 1本2本专科, 除了北京,上海,河北,山东,广东
后面想办法再做吧, 估计会不做了
高考大省与高考小省
我们拿高考大省河南河北然后对比上海和北京, 看下数据
其实这里应该去找数据轴上的最明显特征的线, 具体数据自己分析好了
但是我们暂时只看这几个数据,
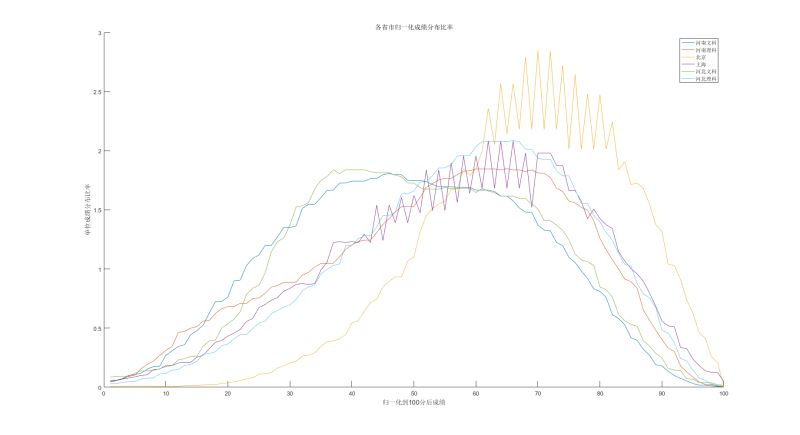
| **** | 平均数 | 中数 | 众数 |
|---|---|---|---|
| 河南文科 | 49.48792233 | 50 | 46 |
| 河南理科 | 54.58292813 | 58 | 65 |
| 北京 | 68.04792125 | 70 | 70 |
| 上海 | 57.56537197 | 60 | 62 |
| 河北文科 | 51.23109382 | 52 | 37 |
| 河北理科 | 58.00918618 | 61 | 66 |
都是前面给出的数据, 我们绘制出来了
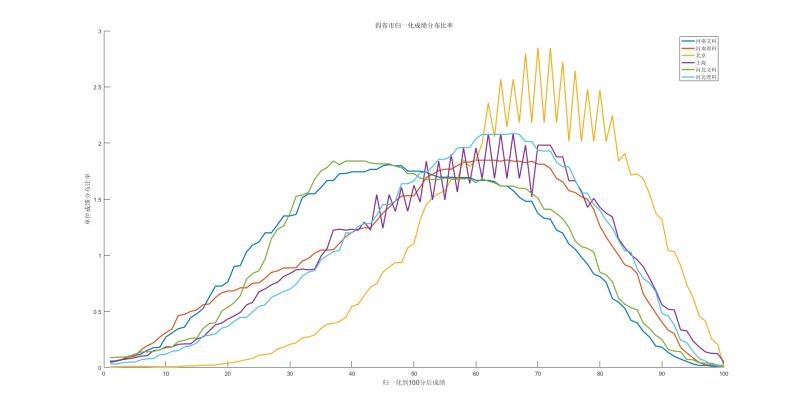
北京的成绩是明显优于河北的,河南和上海的数据其实是一直的,即使是在全部曲线图上也算比较中间的类型了,
总结
搞了半天, 屁用没有,就是手痒然后就搞了一大堆, 越搞越多, 后续还有一堆要做的,
根据本篇数据而言, 北京的成绩是比全国各个省市的成绩要好的,可能与培养方式不同吧,
其实这种分数分布并不一定是培养造成的, 还有部分是各省考试情况不同导致的,所以数据仅供参考, 北京NB
备注
我将所有的数据都存在了 Github 上
https://github.com/SChen1024/GaoKao
有兴趣的可随便拿数据进行分析, 后续还会做完最后一点











