
1.shelve对象的持久存储
不需要关系数据库时,可以用shelve模块作为持久存储Python对象的一个简单的选择。类似于字典,shelf按键访问。值将被pickled并写至由dbm创建和管理的数据库。
1.1 创建一个新shelf
使用shelve最简单的方法就是利用DbfilenameShelf类。它使用dbm存储数据。这个类可以直接使用,也可以通过调用shelve.open()来使用。
import shelve
with shelve.open('test_shelf.db') as s:
s['key1'] = {
'int': 10,
'float': 9.5,
'string': 'Sample data',
}
再次访问这个数据,可以打开shelf,并像字典一样使用它。
import shelve
with shelve.open('test_shelf.db') as s:
existing = s['key1']
print(existing)
运行这两个示例脚本会生成以下输出。
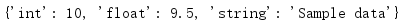
dbm模块不支持多个应用同时写同一个数据库,不过它支持并发的只读客户。如果一个客户没有修改shelf,则可以通过传入flag='r'来告诉shelve以只读方式打开数据库。
import dbm
import shelve
with shelve.open('test_shelf.db', flag='r') as s:
print('Existing:', s['key1'])
try:
s['key1'] = 'new value'
except dbm.error as err:
print('ERROR: {}'.format(err))
如果数据库作为只读数据源打开,并且程序试图修改数据库,那么便会生成一个访问错误异常。具体的异常类型取决于创建数据库时dbm选择的数据库模块。
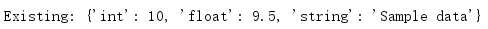
1.2 写回
默认的,shelf不会跟踪对可变对象的修改。这说明,如果存储在shelf中的一个元素的内容有变化,那么shelf必须再次存储整个元素来显式的更新。
import shelve
with shelve.open('test_shelf.db') as s:
print(s['key1'])
s['key1']['new_value'] = 'this was not here before'
with shelve.open('test_shelf.db', writeback=True) as s:
print(s['key1'])
在这个例子中,没有再次存储'key1'的相应字典,所以重新打开shelf时,修改不会保留。

对于shelf中存储的可变对象,要想自动捕获对它们的修改,可以在打开shelf时启用写回(writeback)。writeback标志会让shelf使用内存中缓存以记住从数据库获取的所有对象。shelf关闭时每个缓存对象也被写回到数据库。
import shelve
import pprint
with shelve.open('test_shelf.db', writeback=True) as s:
print('Initial data:')
pprint.pprint(s['key1'])
s['key1']['new_value'] = 'this was not here before'
print('\nModified:')
pprint.pprint(s['key1'])
with shelve.open('test_shelf.db', writeback=True) as s:
print('\nPreserved:')
pprint.pprint(s['key1'])
尽管这会减少程序员犯错的机会,并且使对象持久存储更透明,但是并非所有情况都有必要使用写回模式。打开shelf时缓存会消耗额外的内容,关闭shelf时会暂时将各个缓存对象写回到数据库,这会减慢应用的速度。所有缓存的对象都要写回数据库,因为无法区分它们是否有修改。如果应用读取的数据多于写的数据,那么写回就会影响性能而没有太大意义。

1.3 特定shelf类型
之前的例子都使用了默认的shelf实现。可以使用shelve.open()而不是直接使用某个shelf实现,这是一种常用的用法,特别是使用什么类型的数据库来存储数据并不重要时。不过,有些情况下数据库格式会很重要。在这些情况下,可以直接使用DbfilenameShelf或BsdDbshelf,或者甚至可以派生Shelf来得到一个定制解决方案。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。










