
最近受疫情影响,学校要求每天必须进行健康登记,而我身处大山深处,身体健康,足不出户,奈何总是容易忘记,遂决定手撸一个自动登记的小程序,仅供学习交流之用,话不多说,直接上代码。
配置:Chrom python3.7 selenium库,webdriver等
基本思路,使用selenium模拟浏览器自动登录,需要解决验证码的提取,嵌套表单的提取,弹窗处理,异常处理。
为了防止大家用此网站测试,搞垮服务器,关键网址我已隐藏。
import selenium.webdriver
import time
from bs4 import BeautifulSoup
from selenium.webdriver.common.keys import Keys
driver = selenium.webdriver.Chrome()
url = '你的url'
driver.get(url)
source = driver.find_element_by_xpath('//p[@class="mb-md-5 mb-3 welcome-para"]/a')
#source.get_attribute('href').click()
ur2 = source.get_attribute('href')
driver.get(ur2)#来到登录界面
time.sleep(10)
html = driver.page_source
bs = BeautifulSoup(html,"html.parser")
s = bs.findAll(name='div')[14].text[3:7] #获得验证码
time.sleep(5)
#输入用户名,密码,验证码
driver.find_element_by_name("username").send_keys(你的账号)
driver.find_element_by_name("userpwd").send_keys(你的密码)
driver.find_element_by_name("code").send_keys(s)
driver.find_element_by_name("login").click()
time.sleep(5)
#这里是解决页面跳转问题,用了笨办法
url3='你的url'
driver.get(url3)
time.sleep(5)
driver.switch_to.frame('leftFrame')
html = driver.page_source
bs = BeautifulSoup(html,"html.parser")
url4 = 'https://xsswzx.cdu.edu.cn:81/isp/com_user/'
url5 = bs.findAll('a')[43].get('href')
url6=url4+url5
driver.get(url6)
time.sleep(5)
driver.find_element_by_xpath('//input[@value="【一键登记:无变化】"]').click()
dig_alert = driver.switch_to.alert
dig_alert.accept()
time.sleep(5)
try:
dig_alert = driver.switch_to.alert
dig_alert.accept()
except:
pass
time.sleep(10)
try:
driver.find_element_by_xpath('//input[@value="退出系统"]').click()
except:
driver.close()
print("登记成功")
执行此程序就可以实现登记了,但是并没有实现每天自动登记,下面我们结合Windows通过Anaconda定时调用python脚本,实现每天定时自动登记。
首先编写一个bat脚本:
#此处为引用别人的内容,参考链接:
https://zhuanlan.zhihu.com/p/50057040

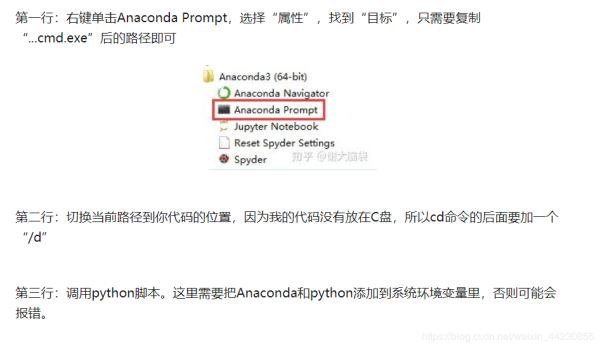
配置好bat文件后
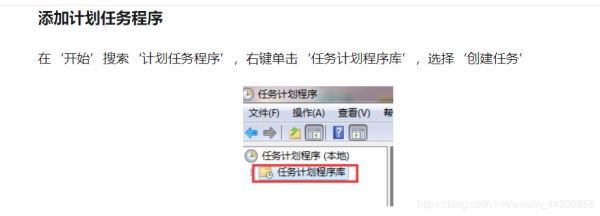
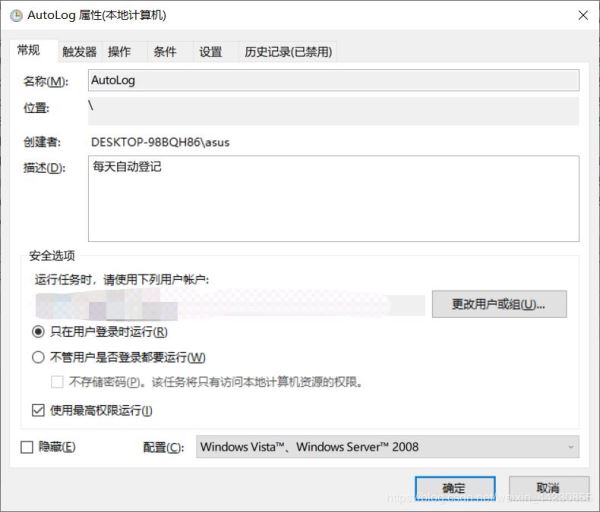
为了使电脑在关机的情况下也能自己开机启动此程序(万一你睡过头了呢,对吧),我们配置如下:
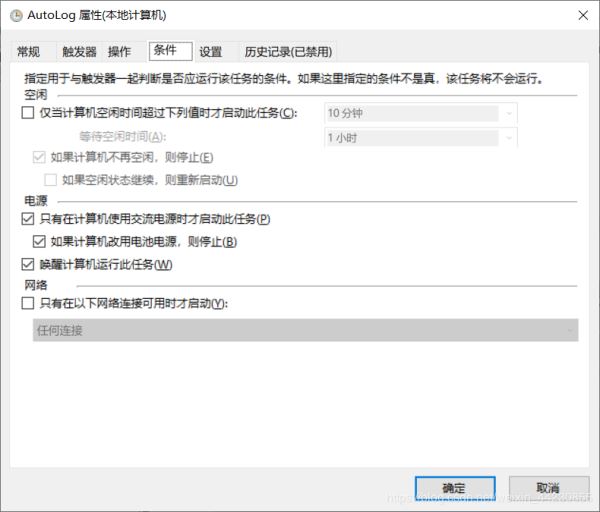
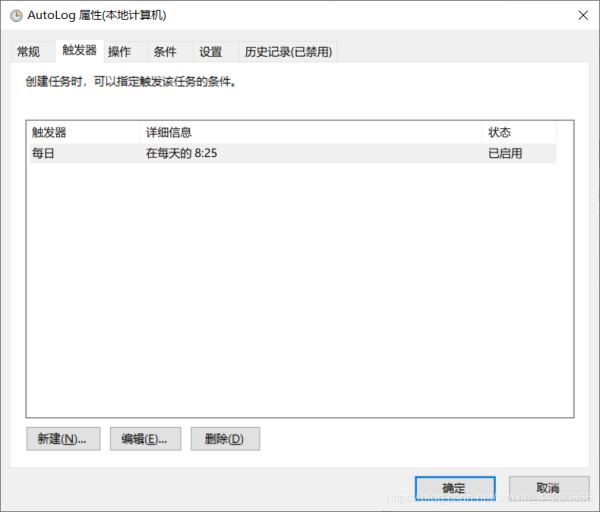
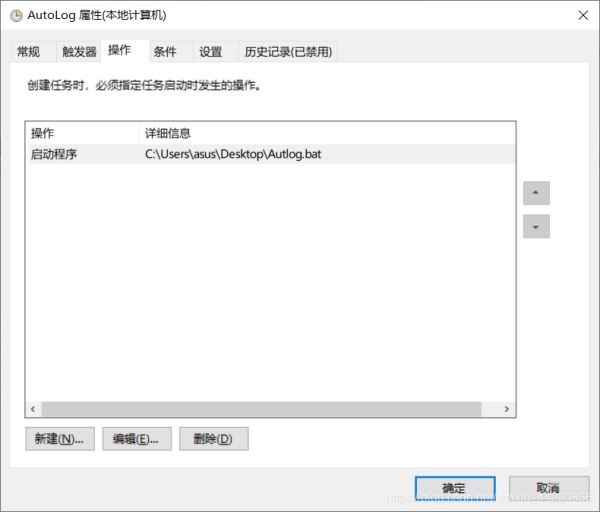
点击确定,至此大功告成。
知识点补充:Python实现自动填写网安早上登记信息
放在这里以后还可以参考!!!
from selenium import webdriver
import time
import schedule
def auto_click():
var1 = 0
file = open('1.txt', 'r')
list1 = []
for num in file:
list1.append(num)
list1 = list(map(int, list1))
while var1 < len(list1):
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
driver.get('http://acm.scu.edu.cn/student/weui/sars2.html?from=singlemessage')
driver.find_element_by_xpath('//*[@id="number"]').send_keys(list1[var1])
driver.find_element_by_xpath('//*[@id="showTooltips"]').click()
time.sleep(5)
driver.quit()
var1 += 1
schedule.every().day.at('16:19').do(auto_click)
while True:
schedule.run_pending()
time.sleep(1)











