
本文实例讲述了Python模块相关知识点。分享给大家供大家参考,具体如下:
1.模块:
定义:用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能),本质就是以.py结尾的python文件(文件名:test.py,对应的模块名:test)。
包:用来从逻辑上组织模块的,本质就是文件夹(目录),必须带有一个__init__.py文件。
导入包的本质就是解释这个包下面的__init__.py文件。
在某个模块下需要导入某一个包下面的内容,需要在包下面的__init__.py文件中修改导入方式,语法为:from . import module_name #.表示当前路径下
模块导入方法:
Import module_name(模块名)===>>实质导出的是模块名称 name.test() Import module_name,m1,m2 from module(模块) import * (函数)===>实质是把代码复制到当前位置(不建议 ) from module import module_name,m1,m2 from module import module_name as modele_name_from_wfb (as取别名)
import本质(路径搜索和搜索路径):
(1)Import module_name ===》把导入的模块的全部代码统一解释一遍,然后赋值给module_name这个变量,例如:module_name=”modele_name.py all code"。【module_name.name】
Import module_name---->执行module_name.py---->module_name.py的路径---sys.path
(2)from module import module_name ==》把module 模块中的module_name部分放到当前文件执行一遍。【name()】
总结:导入模块的本质就是把python文件解释一遍。
2.导入不在同一目录下的文件或者包:
由于导入模块或包的实质是在系统的环境变量(路径)下寻找所导入的文件或者是否存在,存在即可正确执行,否则则需要将文件或者包的绝对路径动态加入到系统的环境变量中。使用sys,os模块
Import sys,os lujin=os.path.dirname(os.path.abspath(__file__)) Sys.path.append(lujin)
目的是:在当前文件中获得指定文件或包的路径(父级目录)。
解释:
os.path.abspath(__file__) 获取当前文件的绝对路径
os.path.dirname:获取当前文件的父级目录。
Sys.path.append(lujin):将所获取的路径加入到系统环境变量中。
3.导入优化
(1) Import module_name
module_name.name()。。
实质:先找模块,在找该模块下的方法.【查找多了效率不高。】
(2) from module_name import name
name() 。。
实质:把模块中的方法拿到指定位置执行一遍。相比import少了多次查找的过程.
4.模块分类
a.标准库(内置)
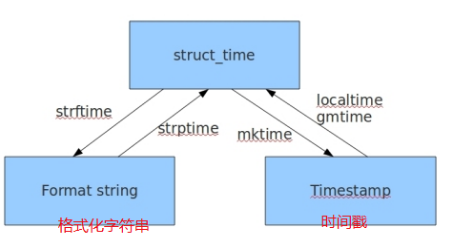
1. time 和datetime.
gmtime():获取标准时间(0时区)
localtime():获取本地时间(东八区)
time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) # %Y对应tm_year %m对应tm.mon

5.json和pickle模块
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
.json和pickle模块只建议dumps和loads一次,否则需要根据之前的顺序依次取出来很麻烦,dumps序列化为字符串。
6. shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式,【可理解为可以实现多次的dumps和、loads】
使用=》
import shelve
d = shelve.open('shelve_test') #打开一个文件
存:d[“key”]=value
取:d,get(“key”)
加密模块
hashlib模块
对中/英文的加密:
import hashlib
m=hashlib.md5()
m.update(b"Hello")
m.update("It's me 你好".encode(encoding='utf-8'))
对信息的加密:
import hmac m=hmac.new(b'天王盖地虎', '宝塔镇河妖'.encode(encoding='utf-8')
b'天王盖地虎':必须是bytes类型
'宝塔镇河妖'.encode(encoding='utf-8':对含有中文的需要进行编码(encode)成二进制。主要是有无b的区别。
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python文件与目录操作技巧汇总》、《Python文本文件操作技巧汇总》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。










