
当我们使用 tensorflow 训练神经网络的时候,模型持久化对于我们的训练有很重要的作用。
如果我们的神经网络比较复杂,训练数据比较多,那么我们的模型训练就会耗时很长,如果在训练过程中出现某些不可预计的错误,导致我们的训练意外终止,那么我们将会前功尽弃。为了避免这个问题,我们就可以通过模型持久化(保存为CKPT格式)来暂存我们训练过程中的临时数据。
如果我们训练的模型需要提供给用户做离线的预测,那么我们只需要前向传播的过程,只需得到预测值就可以了,这个时候我们就可以通过模型持久化(保存为PB格式)只保存前向传播中需要的变量并将变量的值固定下来,这个时候只需用户提供一个输入,我们就可以通过模型得到一个输出给用户。
保存为 CKPT 格式的模型
定义运算过程
声明并得到一个 Saver
通过 Saver.save 保存模型
# coding=UTF-8 支持中文编码格式
import tensorflow as tf
import shutil
import os.path
MODEL_DIR = "model/ckpt"
MODEL_NAME = "model.ckpt"
# if os.path.exists(MODEL_DIR): 删除目录
# shutil.rmtree(MODEL_DIR)
if not tf.gfile.Exists(MODEL_DIR): #创建目录
tf.gfile.MakeDirs(MODEL_DIR)
#下面的过程你可以替换成CNN、RNN等你想做的训练过程,这里只是简单的一个计算公式
input_holder = tf.placeholder(tf.float32, shape=[1], name="input_holder") #输入占位符,并指定名字,后续模型读取可能会用的
W1 = tf.Variable(tf.constant(5.0, shape=[1]), name="W1")
B1 = tf.Variable(tf.constant(1.0, shape=[1]), name="B1")
_y = (input_holder * W1) + B1
predictions = tf.greater(_y, 50, name="predictions") #输出节点名字,后续模型读取会用到,比50大返回true,否则返回false
init = tf.global_variables_initializer()
saver = tf.train.Saver() #声明saver用于保存模型
with tf.Session() as sess:
sess.run(init)
print "predictions : ", sess.run(predictions, feed_dict={input_holder: [10.0]}) #输入一个数据测试一下
saver.save(sess, os.path.join(MODEL_DIR, MODEL_NAME)) #模型保存
print("%d ops in the final graph." % len(tf.get_default_graph().as_graph_def().node)) #得到当前图有几个操作节点
for op in tf.get_default_graph().get_operations(): #打印模型节点信息
print (op.name, op.values())
运行后生成的文件如下:
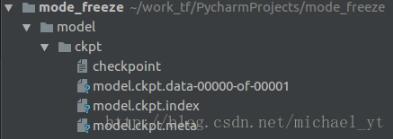
checkpoint : 记录目录下所有模型文件列表
ckpt.data : 保存模型中每个变量的取值
ckpt.meta : 保存整个计算图的结构
保存为 PB 格式模型
定义运算过程
通过 get_default_graph().as_graph_def() 得到当前图的计算节点信息
通过 graph_util.convert_variables_to_constants 将相关节点的values固定
通过 tf.gfile.GFile 进行模型持久化
# coding=UTF-8
import tensorflow as tf
import shutil
import os.path
from tensorflow.python.framework import graph_util
# MODEL_DIR = "model/pb"
# MODEL_NAME = "addmodel.pb"
# if os.path.exists(MODEL_DIR): 删除目录
# shutil.rmtree(MODEL_DIR)
#
# if not tf.gfile.Exists(MODEL_DIR): #创建目录
# tf.gfile.MakeDirs(MODEL_DIR)
output_graph = "model/pb/add_model.pb"
#下面的过程你可以替换成CNN、RNN等你想做的训练过程,这里只是简单的一个计算公式
input_holder = tf.placeholder(tf.float32, shape=[1], name="input_holder")
W1 = tf.Variable(tf.constant(5.0, shape=[1]), name="W1")
B1 = tf.Variable(tf.constant(1.0, shape=[1]), name="B1")
_y = (input_holder * W1) + B1
# predictions = tf.greater(_y, 50, name="predictions") #比50大返回true,否则返回false
predictions = tf.add(_y, 10,name="predictions") #做一个加法运算
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print "predictions : ", sess.run(predictions, feed_dict={input_holder: [10.0]})
graph_def = tf.get_default_graph().as_graph_def() #得到当前的图的 GraphDef 部分,通过这个部分就可以完成重输入层到输出层的计算过程
output_graph_def = graph_util.convert_variables_to_constants( # 模型持久化,将变量值固定
sess,
graph_def,
["predictions"] #需要保存节点的名字
)
with tf.gfile.GFile(output_graph, "wb") as f: # 保存模型
f.write(output_graph_def.SerializeToString()) # 序列化输出
print("%d ops in the final graph." % len(output_graph_def.node))
print (predictions)
# for op in tf.get_default_graph().get_operations(): 打印模型节点信息
# print (op.name)
*GraphDef:这个属性记录了tensorflow计算图上节点的信息。
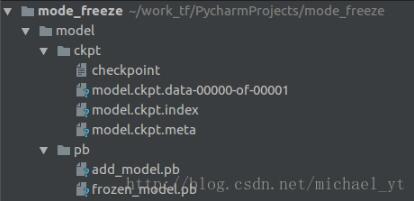
add_model.pb : 里面保存了重输入层到输出层这个计算过程的计算图和相关变量的值,我们得到这个模型后传入一个输入,既可以得到一个预估的输出值
CKPT 转换成 PB格式
通过传入 CKPT 模型的路径得到模型的图和变量数据
通过 import_meta_graph 导入模型中的图
通过 saver.restore 从模型中恢复图中各个变量的数据
通过 graph_util.convert_variables_to_constants 将模型持久化
# coding=UTF-8
import tensorflow as tf
import os.path
import argparse
from tensorflow.python.framework import graph_util
MODEL_DIR = "model/pb"
MODEL_NAME = "frozen_model.pb"
if not tf.gfile.Exists(MODEL_DIR): #创建目录
tf.gfile.MakeDirs(MODEL_DIR)
def freeze_graph(model_folder):
checkpoint = tf.train.get_checkpoint_state(model_folder) #检查目录下ckpt文件状态是否可用
input_checkpoint = checkpoint.model_checkpoint_path #得ckpt文件路径
output_graph = os.path.join(MODEL_DIR, MODEL_NAME) #PB模型保存路径
output_node_names = "predictions" #原模型输出操作节点的名字
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=True) #得到图、clear_devices :Whether or not to clear the device field for an `Operation` or `Tensor` during import.
graph = tf.get_default_graph() #获得默认的图
input_graph_def = graph.as_graph_def() #返回一个序列化的图代表当前的图
with tf.Session() as sess:
saver.restore(sess, input_checkpoint) #恢复图并得到数据
print "predictions : ", sess.run("predictions:0", feed_dict={"input_holder:0": [10.0]}) # 测试读出来的模型是否正确,注意这里传入的是输出 和输入 节点的 tensor的名字,不是操作节点的名字
output_graph_def = graph_util.convert_variables_to_constants( #模型持久化,将变量值固定
sess,
input_graph_def,
output_node_names.split(",") #如果有多个输出节点,以逗号隔开
)
with tf.gfile.GFile(output_graph, "wb") as f: #保存模型
f.write(output_graph_def.SerializeToString()) #序列化输出
print("%d ops in the final graph." % len(output_graph_def.node)) #得到当前图有几个操作节点
for op in graph.get_operations():
print(op.name, op.values())
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("model_folder", type=str, help="input ckpt model dir") #命令行解析,help是提示符,type是输入的类型,
# 这里运行程序时需要带上模型ckpt的路径,不然会报 error: too few arguments
aggs = parser.parse_args()
freeze_graph(aggs.model_folder)
# freeze_graph("model/ckpt") #模型目录
以上这篇关于Tensorflow 模型持久化详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。










