
快速排序的基本思想:首先选定一个数组中的一个初始值,将数组中比该值小的放在左边,比该值大的放在右边,然后分别对左边的数组进行如上的操作,对右边的数组进行如上的操作。(分治+递归)
1.利用匿名函数lambda
匿名函数的基本用法func_name = lambda x:array,冒号左边的x代表传入的参数,冒号右边的array代表返回值,当然名字是可以自己取的。
quick_sort = lambda array: \
array if len(array) <= 1 \
else quick_sort([item for item in array[1:] if item <= array[0]]) \
+ [array[0]] + \
quick_sort([item for item in array[1:] if item > array[0]])
2.将匿名函数拆解封装为函数
def func2(array):
if len(array)<=1:
return array
tmp = array[0]
left = [x for x in array[1:] if x<=tmp]
right = [x for x in array[1:] if x>tmp]
return func2(left) + [tmp] + func2(right)
3.网上常见的
def func2(array,left,right):
if left>=right:
return
low=left
high=right
tmp=array[low]
while left<right:
while left<right and array[right]>tmp:
right-=1
array[left] = array[right]
while left<right and array[left]<=tmp:
left+=1
array[right]=array[left]
array[right]=tmp
func2(array,low,left-1)
func2(array,left+1,high)
4.算法导论里面的
def func3(array, l, r):
if l < r:
q = partition(array, l, r)
func3(array, l, q - 1)
func3(array, q + 1, r)
def partition(array, l, r):
x = array[r]
i = l - 1
for j in range(l, r):
if array[j] <= x:
i += 1
array[i], array[j] = array[j], array[i]
array[i + 1], array[r] = array[r], array[i + 1]
return i + 1
5.利用栈实现非递归版本
def func4(array, l, r):
if l >= r:
return
stack = []
stack.append(l)
stack.append(r)
while stack:
low = stack.pop(0)
high = stack.pop(0)
if high - low <= 0:
continue
x = array[high]
i = low - 1
for j in range(low, high):
if array[j] <= x:
i += 1
array[i], array[j] = array[j], array[i]
array[i + 1], array[high] = array[high], array[i + 1]
stack.extend([low, i, i + 2, high])
6.python内置的
sorted(array)
本来是想利用装饰器来测一下每个函数的运行时间的,但是由于快排里面存在递归,使用装饰器会报错,就只好一个个计算了。这里还是贴一下用装饰器计算时间的代码:
def count_time(func):
@wraps(func)
def helper(func,*args,**kwargs):
start=time()
result = func(*args,**kwargs)
end=time()
print("函数:", func.__name__, "运行时间:", round(end - start, 4), "s")
return result
return helper
这里我们的输入是随机生成的在0-100间的整数,我们测试一下在不同数量下的消耗时间:
from functools import wraps
from random import randint
from time import time
func1_start =time()
res = quick_sort(array)
func1_end =time()
print("函数:func1 运行时间:", round(func1_end - func1_start, 4), "s")
func2_start =time()
func2(array)
func2_end =time()
print("函数:func2 运行时间:", round(func2_end - func2_start, 4), "s")
func3_start =time()
func3(array,0,len(array)-1)
func3_end =time()
print("函数:func3 运行时间:", round(func3_end - func3_start, 4), "s")
func4_start =time()
func4(array,0,len(array)-1)
func4_end =time()
print("函数:func4 运行时间:", round(func4_end - func4_start, 4), "s")
func5_start =time()
func5(array,0,len(array)-1)
func5_end =time()
print("函数:func5 运行时间:", round(func5_end - func5_start, 4), "s")
func6_start =time()
sorted(array)
func6_end =time()
print("函数:func6 运行时间:", round(func6_end - func6_start, 4), "s")
输入array的定义:
array = [randint(0,100) for i in range(5000)]
需要注意的是,随着数据量的增加,方法4,也就是算法导论中的会出现以下问题:

这是因为python中的递归深度是有一定限制的,可以使用如下方法暂时解决该问题:
import sys sys.setrecursionlimit(100000)
同时,方法4还会出现内存溢出问题,方法4也太坑了。

最后对比一下这些方法消耗的时间:
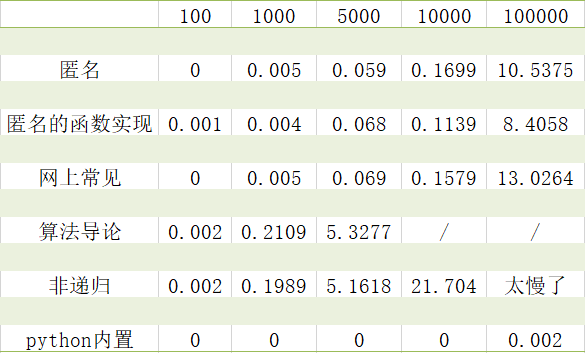
总结:
方法一、方法二速度较快,同时也较好理解,想要学会快速排序,只要记住方法二即可;
python内置的排序速度还是最快的呀;
以上所述是小编给大家介绍的python快速排序的实现及运行时间比较,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!











