
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法。分享给大家供大家参考,具体如下:
决策树
决策树(DTs)是一种用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值。
例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况。树越深,决策规则越复杂,模型也越合适。
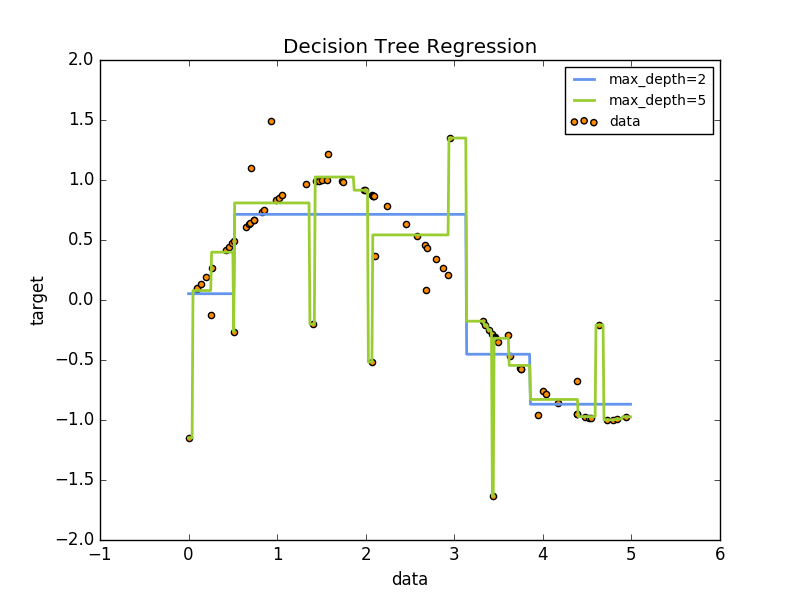
决策树的一些优势是:
决策树的缺点包括:
分类
决策树分类器(DecisionTreeClassifier)是一个能够在数据集上执行多类分类的类。
与其他分类器一样,决策树分类器以输入两个数组作为输入:数组X,稀疏或密集,[n_samples,n_features]保存训练样本,以及数组Y的整数值,[n_samples],保存训练样本的类标签:
>>> from sklearn import tree >>> X = [[0, 0], [1, 1]] >>> Y = [0, 1] >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
模型可以用来预测样本的类别:
>>> clf.predict([[2., 2.]]) array([1])
或者,可以预测每个类的概率,在叶片上同一类的训练样本的分数
>>> clf.predict_proba([[2., 2.]]) array([[ 0., 1.]])
DecisionTreeClassifier可以同时进行二进制(其中标签为[- 1,1])分类和多类(标签为[0],……,k - 1])分类。
使用虹膜数据集,我们可以构建如下的树:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> iris = load_iris() >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(iris.data, iris.target)
训练之后,我们可以使用export_graphviz 将树导出为Graphviz格式。下面是一个在整个iris(虹膜)数据集上输出的树示例:
>>> with open("iris.dot", 'w') as f:
... f = tree.export_graphviz(clf, out_file=f)
然后我们可以使用Graphviz的dot工具来创建一个PDF文件(或者任何其他受支持的文件类型):dot -Tpdf iris.dot -o iris.pdf
>>> import os
>>> os.unlink('iris.dot')
或者,如果我们安装了Python模块pydotplus,我们可以在Python中直接生成PDF文件(或任何其他受支持的文件类型):
>>> import pydotplus
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = pydotplus.graph_from_dot_data(dot_data)
>>> graph.write_pdf("iris.pdf")
export_graphviz exporter 还支持各种各样的选项,包括根据它们的类(或用于回归的值)着色节点,如果需要的话,还可以使用显式变量和类名IPython还可以使用Image()函数来显示这些情节:
>>> from IPython.display import Image
>>> dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
>>> graph = pydotplus.graph_from_dot_data(dot_data)
>>> Image(graph.create_png())
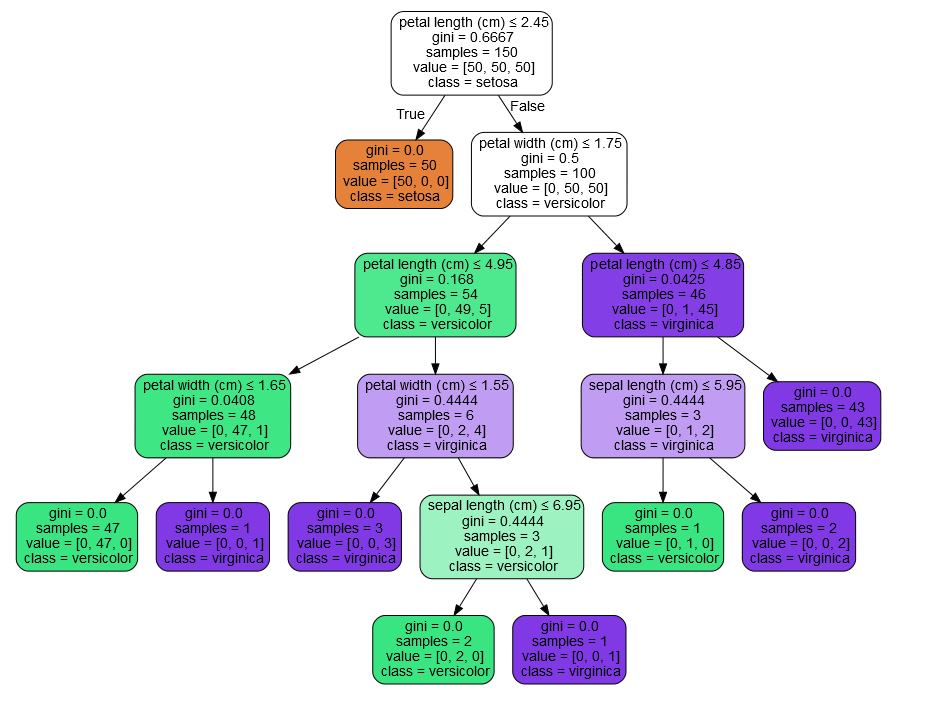
模型可以用来预测样本的类别:
>>> clf.predict(iris.data[:1, :]) array([0])
或者,可以预测每个类的概率,这是同一类在叶子中的训练样本的分数:
>>> clf.predict_proba(iris.data[:1, :]) array([[ 1., 0., 0.]])
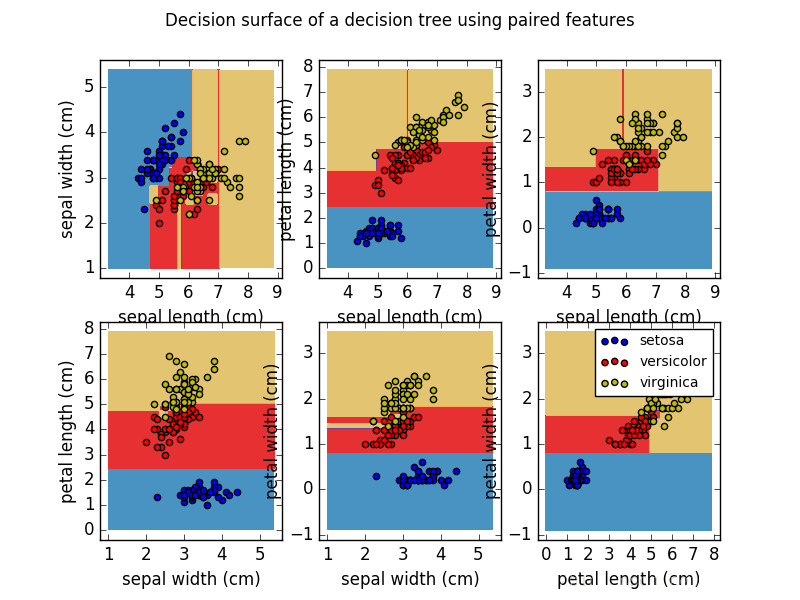
Examples:
Plot the decision surface of a decision tree on the iris dataset
回归
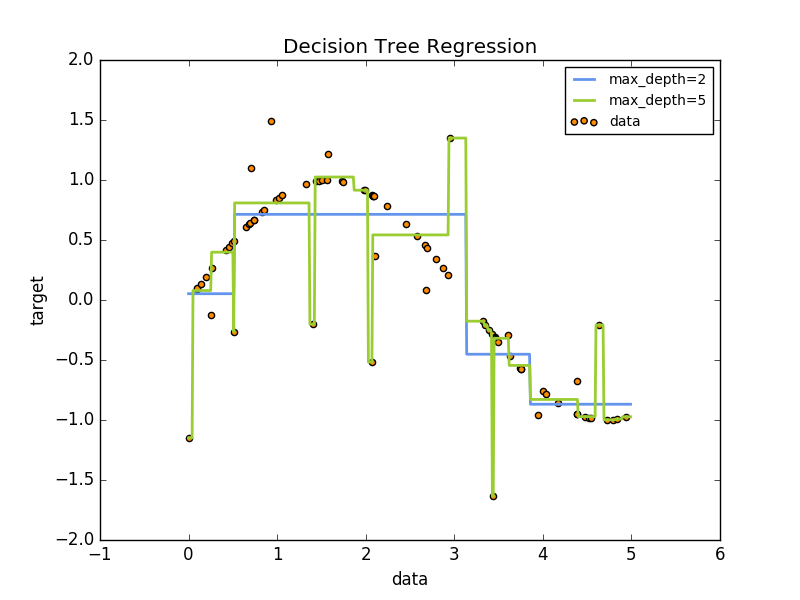
使用决策树类回归,决策树也可以应用于回归问题。
在分类设置中,fit方法将数组X和y作为参数,只有在这种情况下,y被期望有浮点值而不是整数值:
>>> from sklearn import tree >>> X = [[0, 0], [2, 2]] >>> y = [0.5, 2.5] >>> clf = tree.DecisionTreeRegressor() >>> clf = clf.fit(X, y) >>> clf.predict([[1, 1]]) array([ 0.5])
Examples:
多输出问题
一个多输出问题是一个受监督的学习问题,有几个输出可以预测,即当Y是一个二维数组[n_samples,n_output]。
当输出之间没有相关性时,解决这类问题的一个非常简单的方法是建立n个独立的模型,即每一个输出,然后使用这些模型独立地预测每一个输出。
然而,因为可能与相同输入相关的输出值本身是相关的,通常更好的方法是构建一个能够同时预测所有n输出的单一模型。首先,它需要较低的培训时间,因为只构建了一个估计值。其次,结果估计量的泛化精度通常会增加。
对于决策树,这种策略可以很容易地用于支持多输出问题。这需要以下更改:
这个模块提供了支持多输出问题的方法,通过DecisionTreeClassifier 和DecisionTreeRegressor实现这个策略。
如果决策树符合大小(n_samples,n_output)的输出数组Y,那么得到的估计值将是:
predict_proba上输出类概率的n_output数组。多输出决策树回归中显示了多输出树的回归。在这个例子中,输入X是一个单一的实际值,输出Y是X的正弦和余弦。
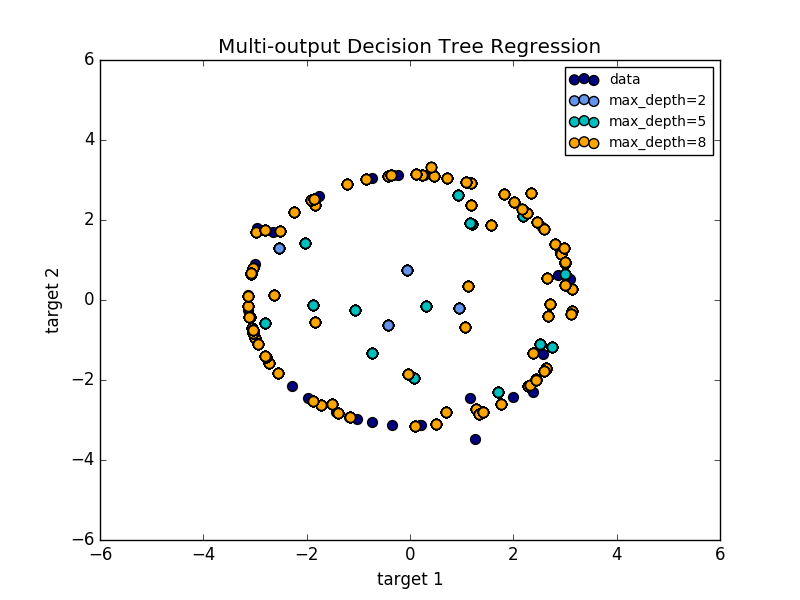
Examples:
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python加密解密算法与技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。











