
最近人人上看到有好友总是使用软件抢沙发,便决定用Python也写一个玩玩
一、状态回复表单POST
同样使用chrome开发者工具抓包
红色选择选中部分为必须提交的部分
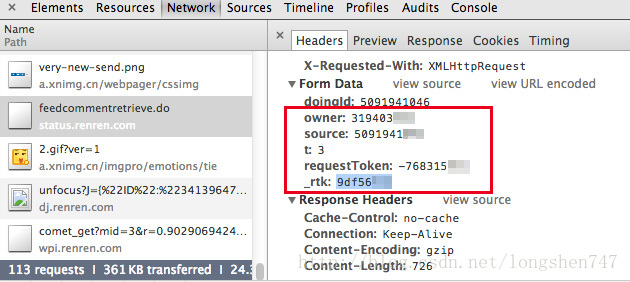
提交表单的内容
postdata = {
'c': content, #1 你要评论的内容
'owner': owner, #2 该状态的所有者ID
'source': source, #3 该状态的ID
't': 3, #4 这条不用修改
'requestToken': xxx, #5 上图选中部分
'_rtk': 'xxx', #6 上图选中部分
}
二、抢沙发思路
每个20s访问一下人人主页,使用BeautifulSoup抓取data-id(对应owner)、data-source(对应source)
模拟表单提交即可完成抢沙发
TARGET_ID 集合存放需要抢沙发的好友ID(data-id)
REPLY_ID 集合存放已经回复过的状态ID(data-source)
通过上述两个集合保证不重复评论,且只评论指定好友的状态
#coding=utf8
import re
import urllib
import urllib2
import time
from bs4 import BeautifulSoup
__author__ = 'SnOw'
COOKIE = '你自己COOKIE'
HEADERS = {'cookie': COOKIE,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36'
}
TARGET_ID = set(['5002986XX']) #存放需要抢沙发的好友ID
REPLY_ID = set()
def load_status():
URL = 'http://www.renren.com/'
req = urllib2.Request(URL, headers=HEADERS)
page = ''
try:
page = urllib2.urlopen(req).read()
except:
print 'urlopen error'
soup = BeautifulSoup(page)
for i in soup.find_all('figure'):
# print i.get('data-id')
if i.get('data-id') in TARGET_ID:
owner_id = i.get('data-id')
source_id = i.get('data-source')
if source_id not in REPLY_ID:
auto_reply(owner_id, source_id)
print i.get('data-id') + ' ' + source_id
else:
print 'replyed this status'
def auto_reply(owner, source):
url = 'http://status.renren.com/feedcommentreply.do?fin=0&ft=status&ff_id=' + str(owner)
content = '(shafa10) ' + time.strftime('于%H时%M分%S秒') + " ~"
postdata = {
'c': content, #1
'owner': owner, #2
'source': source, #3
't': 3, #4
'requestToken': -7683150XX, #5 自己修改
'_rtk': '9df56fXX', #6<span style="white-space:pre;"> </span>自己修改
}
req = urllib2.Request(url, urllib.urlencode(postdata), headers=HEADERS)
page = urllib2.urlopen(req).read()
REPLY_ID.add(source)
while True:
load_status()
time.sleep(20)
print time.strftime('%H:%M:%S')
效果图

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。











