运行下面的脚本,建立测试数据库和表值参数。
--Create DataBase
create database BulkTestDB;
go
use BulkTestDB;
go
--Create Table
Create table BulkTestTable(
Id int primary key,
UserName nvarchar(32),
Pwd varchar(16))
go
--Create Table Valued
CREATE TYPE BulkUdt AS TABLE
(Id int,
UserName nvarchar(32),
Pwd varchar(16))
下面我们使用最简单的Insert语句来插入100万条数据,代码如下:
Stopwatch sw = new Stopwatch();
SqlConnection sqlConn = new SqlConnection(
ConfigurationManager.ConnectionStrings["ConnStr"].ConnectionString);//连接数据库
SqlCommand sqlComm = new SqlCommand();
sqlComm.CommandText = string.Format("insert into BulkTestTable(Id,UserName,Pwd)values(@p0,@p1,@p2)");//参数化SQL
sqlComm.Parameters.Add("@p0", SqlDbType.Int);
sqlComm.Parameters.Add("@p1", SqlDbType.NVarChar);
sqlComm.Parameters.Add("@p2", SqlDbType.VarChar);
sqlComm.CommandType = CommandType.Text;
sqlComm.Connection = sqlConn;
sqlConn.Open();
try
{
//循环插入100万条数据,每次插入10万条,插入10次。
for (int multiply = 0; multiply < 10; multiply++)
{
for (int count = multiply * 100000; count < (multiply + 1) * 100000; count++)
{
sqlComm.Parameters["@p0"].Value = count;
sqlComm.Parameters["@p1"].Value = string.Format("User-{0}", count * multiply);
sqlComm.Parameters["@p2"].Value = string.Format("Pwd-{0}", count * multiply);
sw.Start();
sqlComm.ExecuteNonQuery();
sw.Stop();
}
//每插入10万条数据后,显示此次插入所用时间
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
Console.ReadLine();
耗时图如下:
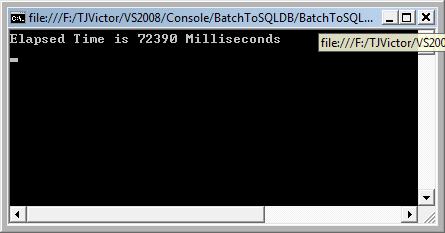
由于运行过慢,才插入10万条就耗时72390 milliseconds,所以我就手动强行停止了。
下面看一下使用Bulk插入的情况:
bulk方法主要思想是通过在客户端把数据都缓存在Table中,然后利用SqlBulkCopy一次性把Table中的数据插入到数据库
代码如下:
public static void BulkToDB(DataTable dt)
{
SqlConnection sqlConn = new SqlConnection(
ConfigurationManager.ConnectionStrings["ConnStr"].ConnectionString);
SqlBulkCopy bulkCopy = new SqlBulkCopy(sqlConn);
bulkCopy.DestinationTableName = "BulkTestTable";
bulkCopy.BatchSize = dt.Rows.Count;
try
{
sqlConn.Open();
if (dt != null && dt.Rows.Count != 0)
bulkCopy.WriteToServer(dt);
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
if (bulkCopy != null)
bulkCopy.Close();
}
}
public static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[]{
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))});
return dt;
}
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = Bulk.GetTableSchema();
for (int count = multiply * 100000; count < (multiply + 1) * 100000; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
Bulk.BulkToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
耗时图如下:
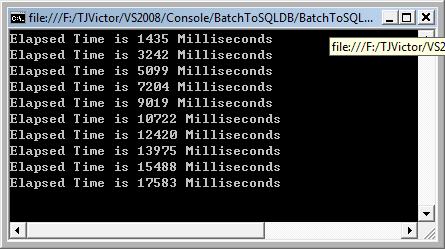
可见,使用Bulk后,效率和性能明显上升。使用Insert插入10万数据耗时72390,而现在使用Bulk插入100万数据才耗时17583。
最后再看看使用表值参数的效率,会另你大为惊讶的。
表值参数是SQL Server 2008新特性,简称TVPs。对于表值参数不熟悉的朋友,可以参考最新的book online,我也会另外写一篇关于表值参数的博客,不过此次不对表值参数的概念做过多的介绍。言归正传,看代码:
public static void TableValuedToDB(DataTable dt)
{
SqlConnection sqlConn = new SqlConnection(
ConfigurationManager.ConnectionStrings["ConnStr"].ConnectionString);
const string TSqlStatement =
"insert into BulkTestTable (Id,UserName,Pwd)" +
" SELECT nc.Id, nc.UserName,nc.Pwd" +
" FROM @NewBulkTestTvp AS nc";
SqlCommand cmd = new SqlCommand(TSqlStatement, sqlConn);
SqlParameter catParam = cmd.Parameters.AddWithValue("@NewBulkTestTvp", dt);
catParam.SqlDbType = SqlDbType.Structured;
//表值参数的名字叫BulkUdt,在上面的建立测试环境的SQL中有。
catParam.TypeName = "dbo.BulkUdt";
try
{
sqlConn.Open();
if (dt != null && dt.Rows.Count != 0)
{
cmd.ExecuteNonQuery();
}
}
catch (Exception ex)
{
throw ex;
}
finally
{
sqlConn.Close();
}
}
public static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[]{
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))});
return dt;
}
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
for (int multiply = 0; multiply < 10; multiply++)
{
DataTable dt = TableValued.GetTableSchema();
for (int count = multiply * 100000; count < (multiply + 1) * 100000; count++)
{
DataRow r = dt.NewRow();
r[0] = count;
r[1] = string.Format("User-{0}", count * multiply);
r[2] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
TableValued.TableValuedToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
耗时图如下:
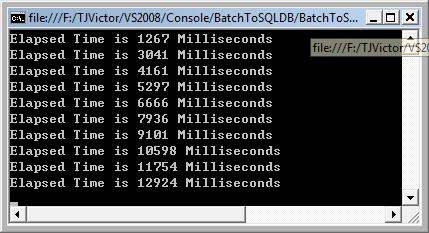
比Bulk还快5秒。
此文原创自CSDN TJVictor












