
根据上面所学的CSS基础语法知识,现在来实现字段的解析。首先还是解析标题。打开网页开发者工具,找到标题所对应的源代码。
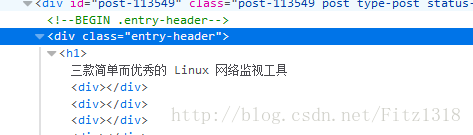
发现是在div class="entry-header"下面的h1节点中,于是打开scrapy shell 进行调试

但是我不想要<h1>这种标签该咋办,这时候就要使用CSS选择器中的伪类方法。如下所示。

注意的是两个冒号。使用CSS选择器真的很方便。同理我用CSS实现字段解析。代码如下
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//div[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//div[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("div.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass
以上所述是小编给大家介绍的CSS选择器实现字段解析,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!










