
笔记中提供了大量的代码示例,需要说明的是,大部分代码示例都是本人所敲代码并进行测试,不足之处,请大家指正~
LZ 本来想先仔细写一写 Hadoop 伪分布式的部署安装,然后介绍一些 HDFS 的内容再来介绍 MapReduce,是在是没有抽出空,今天就简单入门一下 MapReduce 吧。
一、MapReduce 概述
1.MapReduce 是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
2.MapReduce 由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算
二、具体实现
1.先来看一下 Eclipse 中此应用的包结构

2.创建 map 的任务处理类:WCMapper
/*
* 1.Mapper 类的四个泛型中,前两个指定 mapper 输入数据的类型,后两个指定 mapper 输出数据的类型
* KEYIN 是输入的 key 的类型,VALUEIN 是输入的 value 的类型
* KEYOUT 是输出的 key 的类型,VALUEOUT 是输出的 value 的类型
* 2.map 和 reduce 的数据的输入输出都是以 key-value 对的形式封装的
* 3.默认情况下,框架传递给我们的 mapper 的输入数据中,key 是要处理的文本中一行的起始偏移量,为 Long 类型,
* 这一行的内容为 value,为 String 类型的
* 4.后两个泛型的赋值需要我们结合实际情况
* 5.为了在网络中传输时序列化更高效,Hadoop 把 Java 中的 Long 封装为 LongWritable, 把 String 封装为 Text
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
//重写 Mapper 中的 map 方法,MapReduce 框架每读一行数据就调用一次此方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//书写具体的业务逻辑,业务要处理的数据已经被框架传递进来,就是方法的参数中的 key 和 value
//key 是这一行数据的起始偏移量,value 是这一行的文本内容
//1.将 Text 类型的一行的内容转为 String 类型
String line = value.toString();
//2.使用 StringUtils 以空格切分字符串,返回 String[]
String[] words = StringUtils.split(line, " ");
//3.循环遍历 String[],调用 context 的 writer()方法,输出为 key-value 对的形式
//key:单词 value:1
for(String word : words) {
context.write(new Text(word), new LongWritable(1));
}
}
}
2.创建 reduce 的任务处理类:WCReducer:
/*
* 1.Reducer 类的四个泛型中,前两个输入要与 Mapper 的输出相对应。输出需要联系具体情况自定义
*/
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
//框架在 map 处理完之后,将所有的 kv 对缓存起来,进行分组,然后传递一个分组(<key,{values}>,例如:<"hello",{1,1,1,1}>),
//调用此方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)throws IOException, InterruptedException {
//1.定义一个计数器
long count = 0;
//2.遍历 values的 list,进行累加求和
for(LongWritable value : values) {
//使用 LongWritable 的 get() 方法,可以将 一个 LongWritable 类型转为 Long 类型
count += value.get();
}
//3.输出这一个单词的统计结果
context.write(key, new LongWritable(count));
}
}
3.创建一个类,用来描述一个特定的作业:WCRunner,(此类了LZ没有按照规范的模式写)
/**
* 此类用来描述一个特定的作业
* 例:1.该作业使用哪个类作为逻辑处理中的 map,哪个作为 reduce
* 2.指定该作业要处理的数据所在的路径
* 3.指定该作业输出的结果放到哪个路径
*/
public class WCRunner {
public static void main(String[] args) throws Exception {
//1.获取 Job 对象:使用 Job 静态的 getInstance() 方法,传入 Configuration 对象
Configuration conf = new Configuration();
Job wcJob = Job.getInstance(conf);
//2.设置整个 Job 所用的类的 jar 包:使用 Job 的 setJarByClass(),一般传入 当前类.class
wcJob.setJarByClass(WCRunner.class);
//3.设置本 Job 使用的 mapper 和 reducer 的类
wcJob.setMapperClass(WCMapper.class);
wcJob.setReducerClass(WCReducer.class);
//4.指定 reducer 输出数据的 kv 类型 注:若 mapper 和 reducer 的输出数据的 kv 类型一致,可以用如下两行代码设置
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(LongWritable.class);
//5.指定 mapper 输出数据的 kv 类型
wcJob.setMapOutputKeyClass(Text.class);
wcJob.setMapOutputValueClass(LongWritable.class);
//6.指定原始的输入数据存放路径:使用 FileInputFormat 的 setInputPaths() 方法
FileInputFormat.setInputPaths(wcJob, new Path("/wc/srcdata/"));
//7.指定处理结果的存放路径:使用 FileOutputFormat 的 setOutputFormat() 方法
FileOutputFormat.setOutputPath(wcJob, new Path("/wc/output/"));
//8.将 Job 提交给集群运行,参数为 true 表示显示运行状态
wcJob.waitForCompletion(true);
}
}
4.将此项目导出为 jar 文件
步骤:右击项目 ---> Export ---> Java ---> JAR file --->指定导出路径(我指定的为:e:\wc.jar) ---> Finish
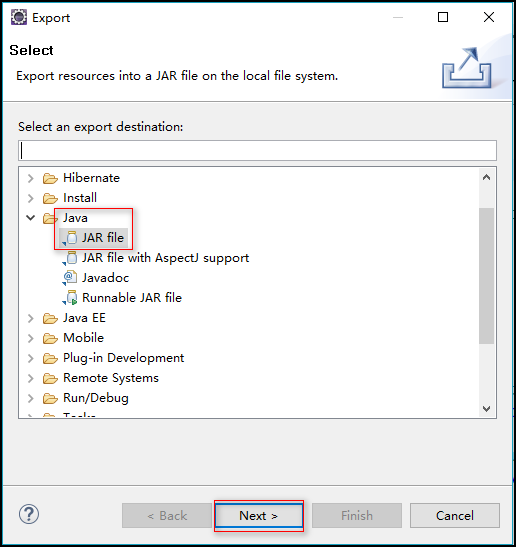
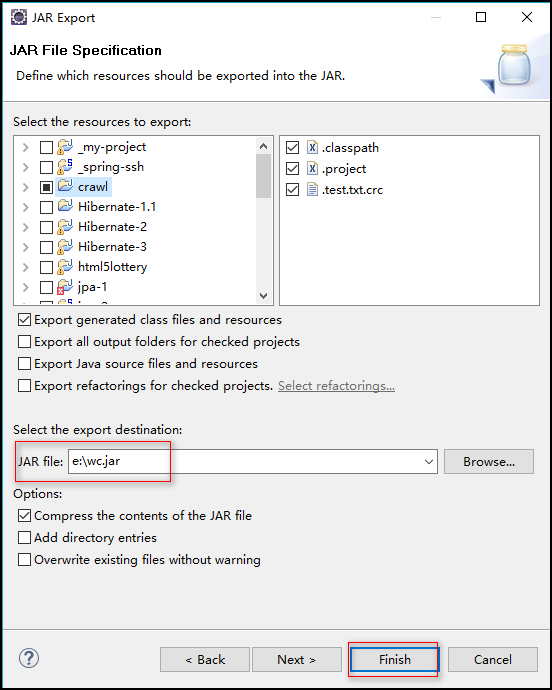
5.将导出的 jar 包上传到 linux 上
LZ使用的方法是:在 SecureCRT 客户端中使用 Alt + p 快捷键打开上传文件的终端,输入 put e"\wc.jar 即可上传

6.创建初始测试文件:words.log
命令: vi words.log 自己输入测试数据即可

7.在 hdfs 中创建存放初始测试文件 words.log 的目录:我们在 WCRunner 中指定的是 /wc/srcdata/
命令:
[hadoop@crawl ~]$ hadoop fs -mkdir /wc
[hadoop@crawl ~]$ hadoop fs -mkdir /wc/srcdata
8.将初始测试文件 words.log 上传到 hdfs 的相应目录
命令:[hadoop@crawl ~]$ hadoop fs -put words.log /wc/srcdata
9.运行 jar 文件
命令:hadoop jar wc.jar com.software.hadoop.mr.wordcount.WCRunner
此命令为 hadoop jar wc.jar 加上 WCRunner类的全类名,程序的入口为 WCRunner 内的 main 方法,运行完此命令便可以看到输出日志信息:
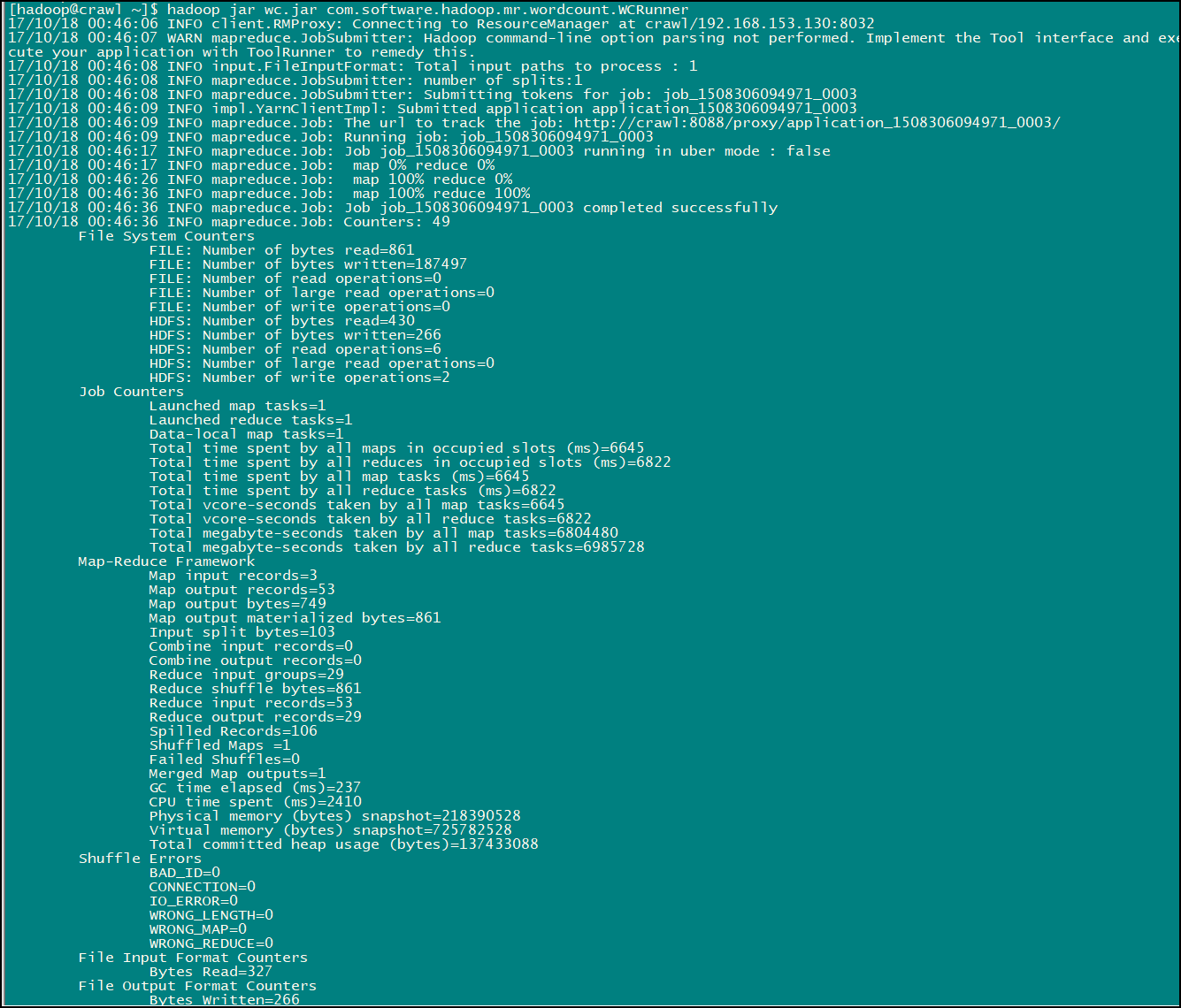
然后前去我们之前配置的存放输出结果的路径(LZ之前设置的为:/wc/output/)就可以看到 MapReduce 的执行结果了
输入命令:hadoop fs -ls /wc/output/ 查看以下 /wc/output/ 路径下的内容

结果数据就在第二个文件中,输入命令:hadoop fs -cat /wc/output/part-r-00000 即可查看:
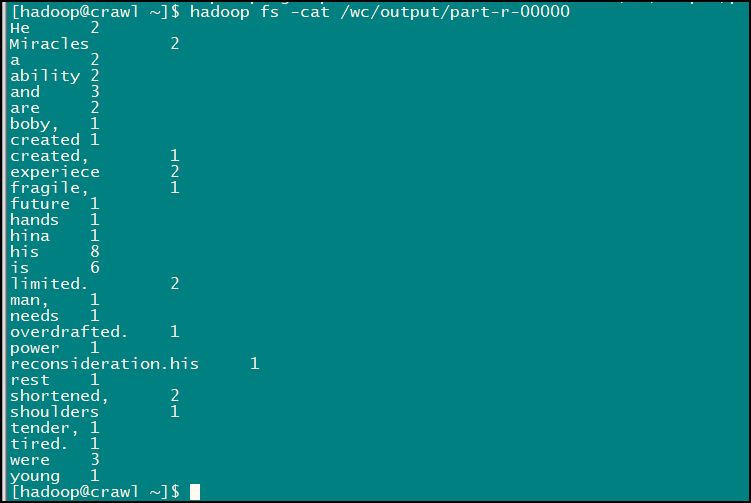
至此我们的这个小应用就完成了,是不是很有意思的,LZ 在实现的时候还是发生了一点小意外:
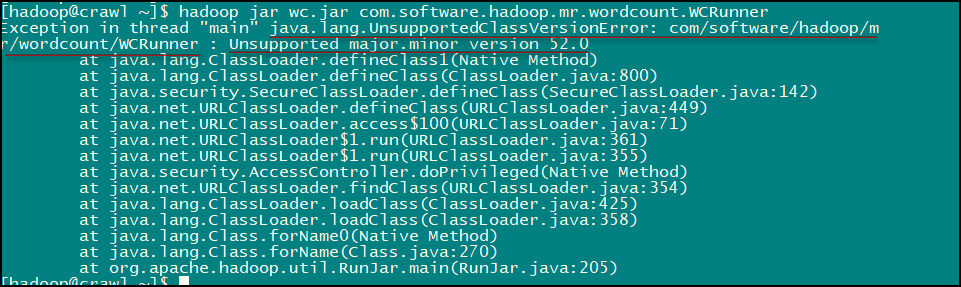
LZ 查阅资料发现这是由于 jdk 版本不一致导致的错误,统一 jdk 版本后便没有问题了。
以上这篇MapReduce 入门之一步步自实现词频统计功能的教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











