
准备4台虚拟机,安装好ol7.7,分配固定ip192.168.168.11 12 13 14,其中192.168.168.11作为master,其他3个作为slave,主节点也同时作为namenode的同时也是datanode,192.168.168.14作为datanode的同时也作为secondary namenodes
首先修改/etc/hostname将主机名改为master、slave1、slave2、slave3
然后修改/etc/hosts文件添加
192.168.168.11 master 192.168.168.12 slave1 192.168.168.13 slave2 192.168.168.14 slave3
然后卸载自带openjdk改为sun jdk,参考https://www.jb51.net/article/190489.htm
配置无密码登陆本机
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
配置互信
master上把公钥传输给各个slave
scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/ scp ~/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/ scp ~/.ssh/id_rsa.pub hadoop@slave3:/home/hadoop/
在slave主机上将master的公钥加入各自的节点上
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
master上安装hadoop
sudo tar -xzvf ~/hadoop-3.2.1.tar.gz -C /usr/local sudo mv hadoop-3.2.1-src/ ./hadoop sudo chown -R hadoop: ./hadoop
.bashrc添加并使之生效
export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
集群配置,/usr/local/hadoop/etc/hadoop目录中有配置文件:
修改core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/nameNode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/dataNode</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>slave3:50090</value> </property> </configuration>
修改mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration>
修改yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
修改hadoop-env.sh找到JAVA_HOME的配置将目录修改为
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
修改workers
[hadoop@master /usr/local/hadoop/etc/hadoop]$ vim workers master slave1 slave2 slave3
最后将配置好的/usr/local/hadoop文件夹复制到其他节点
sudo scp -r /usr/local/hadoop/ slave1:/usr/local/ sudo scp -r /usr/local/hadoop/ slave2:/usr/local/ sudo scp -r /usr/local/hadoop/ slave3:/usr/local/
并且把文件夹owner改为hadoop
sudo systemctl stop firewalld sudo systemctl disable firewalld
关闭防火墙
格式化hdfs,首次运行前运行,以后不用,在任意节点执行都可以/usr/local/hadoop/bin/hadoop namenode –format

看到这个successfuly formatted就是表示成功
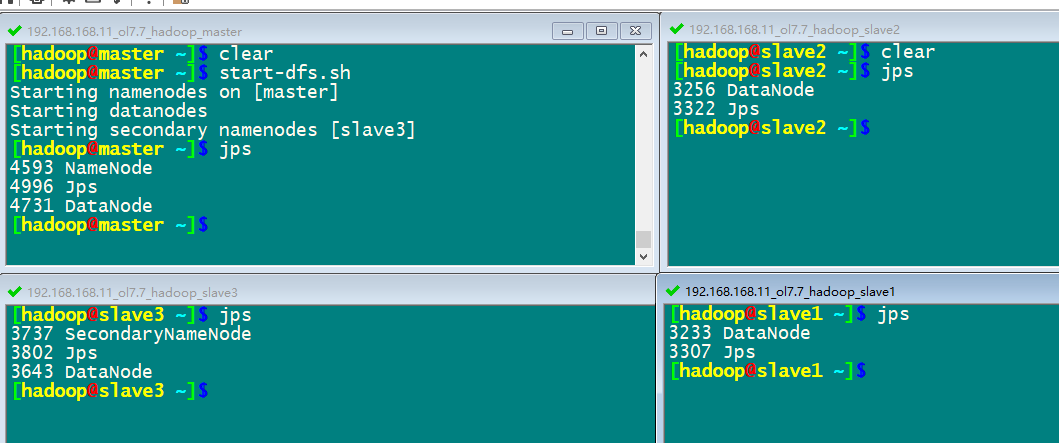
start-dfs.sh启动集群hdfs
jps命令查看运行情况
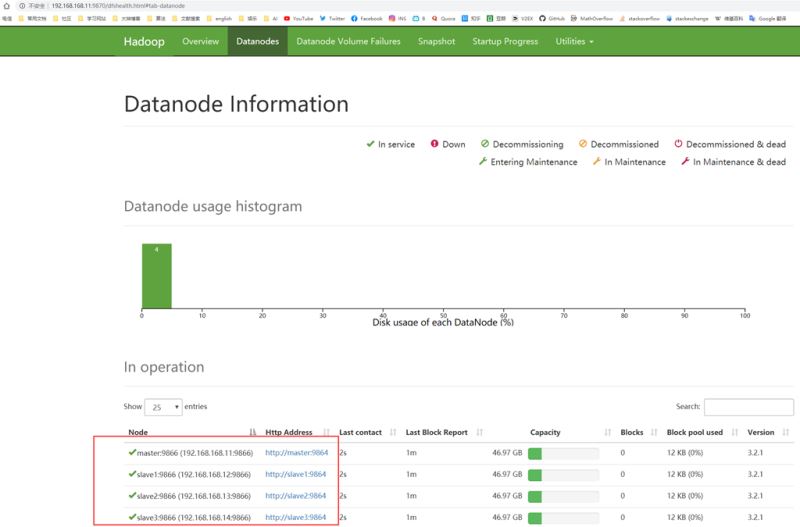
 通过master的9870端口可以网页监控http://192.168.168.11:9870/
通过master的9870端口可以网页监控http://192.168.168.11:9870/
也可以通过命令行查看集群状态hadoop dfsadmin -report
[hadoop@master ~]$ hadoop dfsadmin -report WARNING: Use of this script to execute dfsadmin is deprecated. WARNING: Attempting to execute replacement "hdfs dfsadmin" instead. Configured Capacity: 201731358720 (187.88 GB) Present Capacity: 162921230336 (151.73 GB) DFS Remaining: 162921181184 (151.73 GB) DFS Used: 49152 (48 KB) DFS Used%: 0.00% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (4): Name: 192.168.168.11:9866 (master) Hostname: master Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9796546560 (9.12 GB) DFS Remaining: 40636280832 (37.85 GB) DFS Used%: 0.00% DFS Remaining%: 80.58% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 Name: 192.168.168.12:9866 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9710411776 (9.04 GB) DFS Remaining: 40722415616 (37.93 GB) DFS Used%: 0.00% DFS Remaining%: 80.75% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 Name: 192.168.168.13:9866 (slave2) Hostname: slave2 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9657286656 (8.99 GB) DFS Remaining: 40775540736 (37.98 GB) DFS Used%: 0.00% DFS Remaining%: 80.85% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 Name: 192.168.168.14:9866 (slave3) Hostname: slave3 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 12288 (12 KB) Non DFS Used: 9645883392 (8.98 GB) DFS Remaining: 40786944000 (37.99 GB) DFS Used%: 0.00% DFS Remaining%: 80.87% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Fri Jul 03 11:14:44 CST 2020 Last Block Report: Fri Jul 03 11:10:35 CST 2020 Num of Blocks: 0 [hadoop@master ~]$
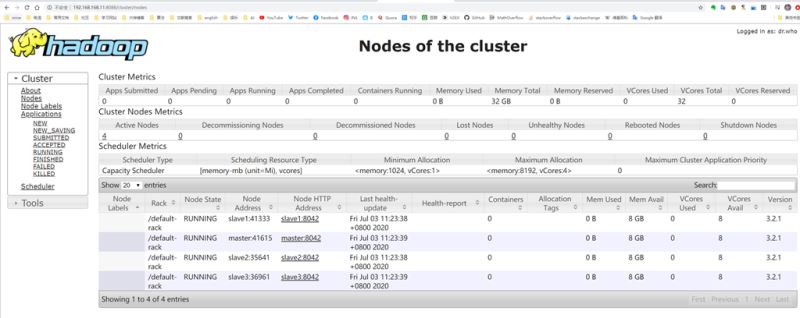
start-yarn.sh可以开启yarn,可以通过master8088端口监控
启动集群命令,可以同时开启hdfs和yarn /usr/local/hadoop/sbin/start-all.sh
停止集群命令 /usr/local/hadoop/sbin/stop-all.sh
就这样,记录过程,以备后查











