
scrapy是目前python使用的最广泛的爬虫框架
架构图如下
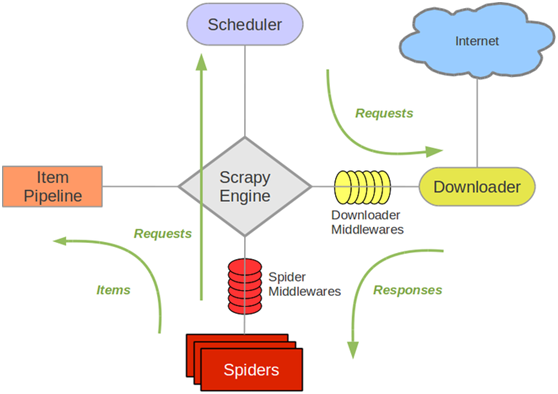
解释:
一。安装
pip install Twisted.whl
pip install Scrapy
Twisted的版本要与安装的python对应,https://jingyan.baidu.com/article/1709ad8027be404634c4f0e8.html
二。代码
本实例采用xpaths解析页面数据
按住shift-右键-在此处打开命令窗口
输入scrapy startproject qiushibaike 创建项目
输入scrapy genspiderqiushibaike 创建爬虫
1>结构
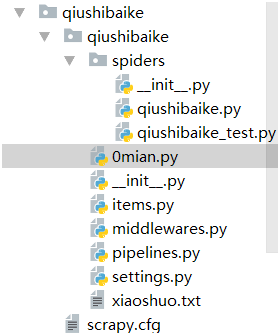
2>qiushibaike.py爬虫文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders.crawl import Rule, CrawlSpider
class BaiduSpider(CrawlSpider):
name = 'qiushibaike'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']#启始页面
#
rules= (
Rule(LinkExtractor(restrict_xpaths=r'//a[@class="contentHerf"]'),callback='parse_item',follow=True),
Rule(LinkExtractor(restrict_xpaths=r'//ul[@class="pagination"]/li/a'),follow=True)
)
def parse_item(self, response):
title=response.xpath('//h1[@class="article-title"]/text()').extract_first().strip() #标题
time=response.xpath(' //span[@class="stats-time"]/text()').extract_first().strip() #发布时间
content=response.xpath('//div[@class="content"]/text()').extract_first().replace(' ','\n') #内容
score=response.xpath('//i[@class="number"]/text()').extract_first().strip() #好笑数
yield({"title":title,"content":content,"time":time,"score":score});
3>pipelines.py 数据管道[code]class QiushibaikePipeline:
class QiushibaikePipeline:
def open_spider(self,spider):#启动爬虫中调用
self.f=open("xiaoshuo.txt","w",encoding='utf-8')
def process_item(self, item, spider):
info=item.get("title")+"\n"+ item.get("time")+" 好笑数"+item.get("score")+"\n"+ item.get("content")+'\n'
self.f.write(info+"\n")
self.f.flush()
def close_spider(self,spider):#关闭爬虫中调用
self.f.close()
4>settings.py
开启ZhonghengPipeline
ITEM_PIPELINES = {
'qiushibaike.pipelines.QiushibaikePipeline': 300,
}
5>0main.py运行
from scrapy.cmdline import execute
execute('scrapy crawl qiushibaike'.split())
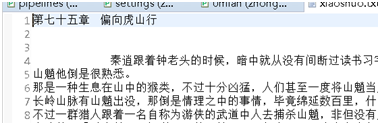
6>结果:
生成xiaohua.txt,里面有下载的笑话文字
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。











