
ShuffleNet是由旷世发表的一个计算效率极高的CNN架构,它是专门为计算能力非常有限的移动设备(例如,10-150 MFLOPs)而设计的。该结构利用组卷积和信道混洗两种新的运算方法,在保证计算精度的同时,大大降低了计算成本。ImageNet分类和MS COCO对象检测实验表明,在40 MFLOPs的计算预算下,ShuffleNet的性能优于其他结构,例如,在ImageNet分类任务上,ShuffleNet的top-1 error 7.8%比最近的MobileNet低。在基于arm的移动设备上,ShuffleNet比AlexNet实际加速了13倍,同时保持了相当的准确性。
Paper:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
Github:https://github.com/zjn-ai/ShuffleNet-keras
网络架构
组卷积
组卷积其实早在AlexNet中就用过了,当时因为GPU的显存不足因而利用组卷积分配到两个GPU上训练。简单来讲,组卷积就是将输入特征图按照通道方向均分成多个大小一致的特征图,如下图所示左面是输入特征图右面是均分后的特征图,然后对得到的每一个特征图进行正常的卷积操作,最后将输出特征图按照通道方向拼接起来就可以了。
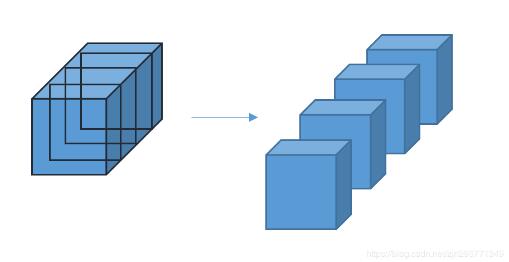
目前很多框架都支持组卷积,但是tensorflow真的不知道在想什么,到现在还是不支持组卷积,只能自己写,因此效率肯定不及其他框架原生支持的方法。组卷积层的代码编写思路就与上面所说的原理完全一致,代码如下。
def _group_conv(x, filters, kernel, stride, groups):
"""
Group convolution
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
# Returns
Output tensor
"""
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
in_channels = K.int_shape(x)[channel_axis]
# number of input channels per group
nb_ig = in_channels // groups
# number of output channels per group
nb_og = filters // groups
gc_list = []
# Determine whether the number of filters is divisible by the number of groups
assert filters % groups == 0
for i in range(groups):
if channel_axis == -1:
x_group = Lambda(lambda z: z[:, :, :, i * nb_ig: (i + 1) * nb_ig])(x)
else:
x_group = Lambda(lambda z: z[:, i * nb_ig: (i + 1) * nb_ig, :, :])(x)
gc_list.append(Conv2D(filters=nb_og, kernel_size=kernel, strides=stride,
padding='same', use_bias=False)(x_group))
return Concatenate(axis=channel_axis)(gc_list)
通道混洗
通道混洗是这篇paper的重点,尽管组卷积大量减少了计算量和参数,但是通道之间的信息交流也受到了限制因而模型精度肯定会受到影响,因此作者提出通道混洗,在不增加参数量和计算量的基础上加强通道之间的信息交流,如下图所示。
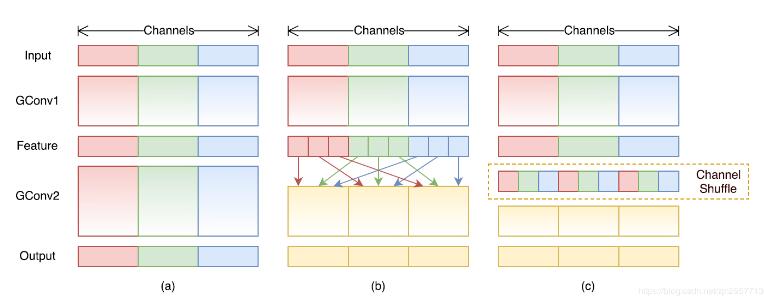
通道混洗层的代码实现很巧妙参考了别人的实现方法。通过下面的代码说明,d代表特征图的通道序号,x是经过通道混洗后的通道顺序。
>>> d = np.array([0,1,2,3,4,5,6,7,8]) >>> x = np.reshape(d, (3,3)) >>> x = np.transpose(x, [1,0]) # 转置 >>> x = np.reshape(x, (9,)) # 平铺 '[0 1 2 3 4 5 6 7 8] --> [0 3 6 1 4 7 2 5 8]'
利用keras后端实现代码:
def _channel_shuffle(x, groups): """ Channel shuffle layer # Arguments x: Tensor, input tensor of with `channels_last` or 'channels_first' data format groups: Integer, number of groups per channel # Returns Shuffled tensor """ if K.image_data_format() == 'channels_last': height, width, in_channels = K.int_shape(x)[1:] channels_per_group = in_channels // groups pre_shape = [-1, height, width, groups, channels_per_group] dim = (0, 1, 2, 4, 3) later_shape = [-1, height, width, in_channels] else: in_channels, height, width = K.int_shape(x)[1:] channels_per_group = in_channels // groups pre_shape = [-1, groups, channels_per_group, height, width] dim = (0, 2, 1, 3, 4) later_shape = [-1, in_channels, height, width] x = Lambda(lambda z: K.reshape(z, pre_shape))(x) x = Lambda(lambda z: K.permute_dimensions(z, dim))(x) x = Lambda(lambda z: K.reshape(z, later_shape))(x) return x
ShuffleNet Unit
ShuffleNet的主要构成单元。下图中,a图为深度可分离卷积的基本架构,b图为1步长时用的单元,c图为2步长时用的单元。
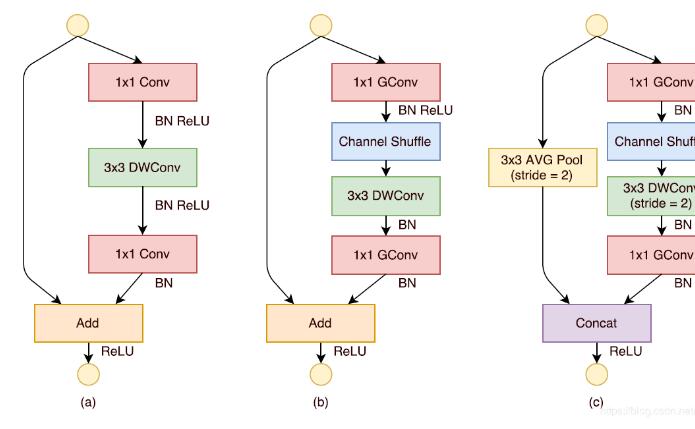
ShuffleNet架构
注意,对于第二阶段(Stage2),作者没有在第一个1×1卷积上应用组卷积,因为输入通道的数量相对较少。
环境
Python 3.6
Tensorlow 1.13.1
Keras 2.2.4
实现
支持channel first或channel last
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 25 18:26:41 2019
@author: zjn
"""
import numpy as np
from keras.callbacks import LearningRateScheduler
from keras.models import Model
from keras.layers import Input, Conv2D, Dropout, Dense, GlobalAveragePooling2D, Concatenate, AveragePooling2D
from keras.layers import Activation, BatchNormalization, add, Reshape, ReLU, DepthwiseConv2D, MaxPooling2D, Lambda
from keras.utils.vis_utils import plot_model
from keras import backend as K
from keras.optimizers import SGD
def _group_conv(x, filters, kernel, stride, groups):
"""
Group convolution
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
# Returns
Output tensor
"""
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
in_channels = K.int_shape(x)[channel_axis]
# number of input channels per group
nb_ig = in_channels // groups
# number of output channels per group
nb_og = filters // groups
gc_list = []
# Determine whether the number of filters is divisible by the number of groups
assert filters % groups == 0
for i in range(groups):
if channel_axis == -1:
x_group = Lambda(lambda z: z[:, :, :, i * nb_ig: (i + 1) * nb_ig])(x)
else:
x_group = Lambda(lambda z: z[:, i * nb_ig: (i + 1) * nb_ig, :, :])(x)
gc_list.append(Conv2D(filters=nb_og, kernel_size=kernel, strides=stride,
padding='same', use_bias=False)(x_group))
return Concatenate(axis=channel_axis)(gc_list)
def _channel_shuffle(x, groups):
"""
Channel shuffle layer
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
groups: Integer, number of groups per channel
# Returns
Shuffled tensor
"""
if K.image_data_format() == 'channels_last':
height, width, in_channels = K.int_shape(x)[1:]
channels_per_group = in_channels // groups
pre_shape = [-1, height, width, groups, channels_per_group]
dim = (0, 1, 2, 4, 3)
later_shape = [-1, height, width, in_channels]
else:
in_channels, height, width = K.int_shape(x)[1:]
channels_per_group = in_channels // groups
pre_shape = [-1, groups, channels_per_group, height, width]
dim = (0, 2, 1, 3, 4)
later_shape = [-1, in_channels, height, width]
x = Lambda(lambda z: K.reshape(z, pre_shape))(x)
x = Lambda(lambda z: K.permute_dimensions(z, dim))(x)
x = Lambda(lambda z: K.reshape(z, later_shape))(x)
return x
def _shufflenet_unit(inputs, filters, kernel, stride, groups, stage, bottleneck_ratio=0.25):
"""
ShuffleNet unit
# Arguments
inputs: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
stage: Integer, stage number of ShuffleNet
bottleneck_channels: Float, bottleneck ratio implies the ratio of bottleneck channels to output channels
# Returns
Output tensor
# Note
For Stage 2, we(authors of shufflenet) do not apply group convolution on the first pointwise layer
because the number of input channels is relatively small.
"""
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
in_channels = K.int_shape(inputs)[channel_axis]
bottleneck_channels = int(filters * bottleneck_ratio)
if stage == 2:
x = Conv2D(filters=bottleneck_channels, kernel_size=kernel, strides=1,
padding='same', use_bias=False)(inputs)
else:
x = _group_conv(inputs, bottleneck_channels, (1, 1), 1, groups)
x = BatchNormalization(axis=channel_axis)(x)
x = ReLU()(x)
x = _channel_shuffle(x, groups)
x = DepthwiseConv2D(kernel_size=kernel, strides=stride, depth_multiplier=1,
padding='same', use_bias=False)(x)
x = BatchNormalization(axis=channel_axis)(x)
if stride == 2:
x = _group_conv(x, filters - in_channels, (1, 1), 1, groups)
x = BatchNormalization(axis=channel_axis)(x)
avg = AveragePooling2D(pool_size=(3, 3), strides=2, padding='same')(inputs)
x = Concatenate(axis=channel_axis)([x, avg])
else:
x = _group_conv(x, filters, (1, 1), 1, groups)
x = BatchNormalization(axis=channel_axis)(x)
x = add([x, inputs])
return x
def _stage(x, filters, kernel, groups, repeat, stage):
"""
Stage of ShuffleNet
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
repeat: Integer, total number of repetitions for a shuffle unit in every stage
stage: Integer, stage number of ShuffleNet
# Returns
Output tensor
"""
x = _shufflenet_unit(x, filters, kernel, 2, groups, stage)
for i in range(1, repeat):
x = _shufflenet_unit(x, filters, kernel, 1, groups, stage)
return x
def ShuffleNet(input_shape, classes):
"""
ShuffleNet architectures
# Arguments
input_shape: An integer or tuple/list of 3 integers, shape
of input tensor
k: Integer, number of classes to predict
# Returns
A keras model
"""
inputs = Input(shape=input_shape)
x = Conv2D(24, (3, 3), strides=2, padding='same', use_bias=True, activation='relu')(inputs)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
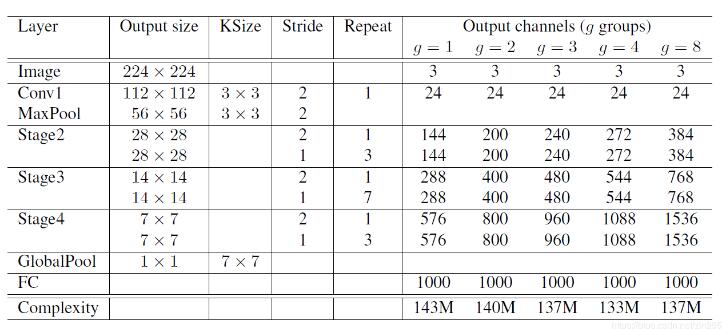
x = _stage(x, filters=384, kernel=(3, 3), groups=8, repeat=4, stage=2)
x = _stage(x, filters=768, kernel=(3, 3), groups=8, repeat=8, stage=3)
x = _stage(x, filters=1536, kernel=(3, 3), groups=8, repeat=4, stage=4)
x = GlobalAveragePooling2D()(x)
x = Dense(classes)(x)
predicts = Activation('softmax')(x)
model = Model(inputs, predicts)
return model
if __name__ == '__main__':
model = ShuffleNet((224, 224, 3), 1000)
#plot_model(model, to_file='ShuffleNet.png', show_shapes=True)
以上这篇keras 实现轻量级网络ShuffleNet教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











