
groupby的函数定义:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
其他的参数解释就看文档吧:链接:pandas.DataFrame.groupby 介绍文档
所见 1 :日常用法
import pandas as pd
df = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周杰伦', '蔡依林', '林俊杰', '周杰伦', '林俊杰', '周杰伦', '田馥甄', '蔡依林', '田馥甄'],
'income' : [4.5, 2.9, 3.8, 3.7, 4.0, 4.1, 1.9, 4.1, 3.2],
'expenditure' : [1.5, 1.9, 2.8, 1.7, 4.1, 2.5, 1.1, 3.4, 1.2]
})
#根据其中一列分组
df_expenditure_mean = df.groupby(['Gender']).mean()
#根据其中两列分组
df_expenditure_mean = df.groupby(['Gender', 'name']).mean()
#只对其中一列求均值
df_expenditure_mean = df.groupby(['Gender', 'name'])['income'].mean()
输出示例:
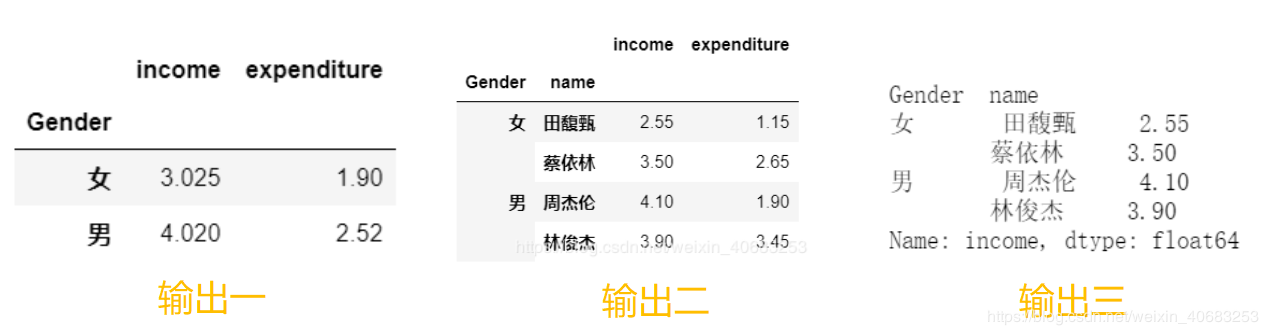
所见 2 :解决groupby.sum() 后层级索引levels上移的问题
上图中的输出二,虽然是 DataFrame 的格式,但是若需要与其他表匹配的时候,这个格式就有些麻烦了。匹配数据时,我们需要的数据格式是:列名都在第一行,数据行中也不能有 Gender 列这样的合并单元格。因此,我们需要做一些调整,将 as_index 改为 False ,默认是 Ture 。
#不以组标签为索引,通过 as_index 来实现 df_expenditure_mean = df.groupby(['Gender', 'name'], as_index=False).mean()
输出:
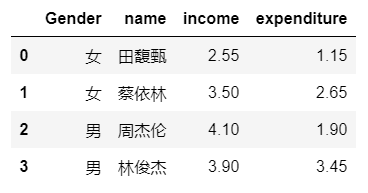
所见 3 :解决groupby.apply() 后层级索引levels上移的问题
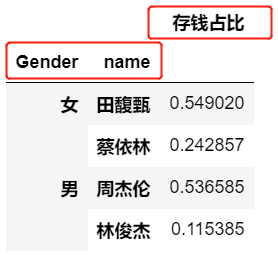
在所见 2 中我们知道,使用参数 as_index 就可使 groupby 的结果不以组标签为索引,但是后来在使用 groupby.apply() 时发现,as_index 参数失去了效果。如下例所示:
# 使用了 as_index=False,但是从输出结果中可见没起到作用 df_apply = df.groupby(['Gender', 'name'], as_index=False).apply(lambda x: sum(x['income']-x['expenditure'])/sum(x['income'])) df_apply = pd.DataFrame(df_apply,columns=['存钱占比'])#转化成dataframe格式
输出:
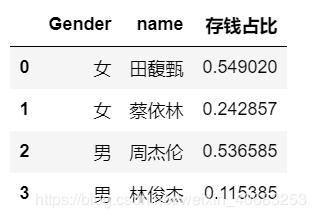
解决办法: 加一句df_apply_index = df_apply.reset_index()
# 加一句df_apply_index = df_apply.reset_index() df_apply = df.groupby(['Gender', 'name'], as_index=False).apply(lambda x: sum(x['income']-x['expenditure'])/sum(x['income'])) df_apply = pd.DataFrame(df_apply,columns=['存钱占比'])#转化成dataframe格式 df_apply_index = df_apply.reset_index()
输出:
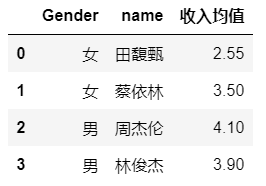
所见 4 :groupby函数的分组结果保存成DataFrame
所见 1 中的输出三,明显是 Series ,我们需要将其转化为 DataFrame 格式的数据。
#只对其中一列求均值,并转化为 DataFrame
df_expenditure_mean = df.groupby(['Gender', 'name'], as_index=False)['income'].mean()
df_expenditure_mean = pd.DataFrame(df_expenditure_mean)#转化成dataframe格式
df_expenditure_mean.rename(columns={'income':'收入均值'}, inplace = True)
输出:
到此这篇关于 DataFrame.groupby() 所见的各种用法详解的文章就介绍到这了,更多相关 DataFrame.groupby()用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!











