
我就废话不多说了,大家还是直接看代码吧!
#加载keras模块
from __future__ import print_function
import numpy as np
np.random.seed(1337) # for reproducibility
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD, Adam, RMSprop
from keras.utils import np_utils
import matplotlib.pyplot as plt
%matplotlib inline
#写一个LossHistory类,保存loss和acc
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = {'batch':[], 'epoch':[]}
self.accuracy = {'batch':[], 'epoch':[]}
self.val_loss = {'batch':[], 'epoch':[]}
self.val_acc = {'batch':[], 'epoch':[]}
def on_batch_end(self, batch, logs={}):
self.losses['batch'].append(logs.get('loss'))
self.accuracy['batch'].append(logs.get('acc'))
self.val_loss['batch'].append(logs.get('val_loss'))
self.val_acc['batch'].append(logs.get('val_acc'))
def on_epoch_end(self, batch, logs={}):
self.losses['epoch'].append(logs.get('loss'))
self.accuracy['epoch'].append(logs.get('acc'))
self.val_loss['epoch'].append(logs.get('val_loss'))
self.val_acc['epoch'].append(logs.get('val_acc'))
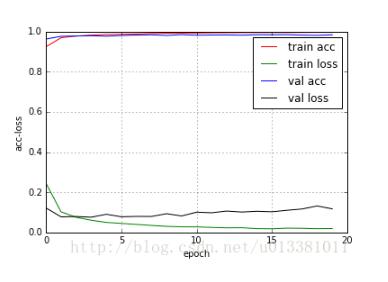
def loss_plot(self, loss_type):
iters = range(len(self.losses[loss_type]))
plt.figure()
# acc
plt.plot(iters, self.accuracy[loss_type], 'r', label='train acc')
# loss
plt.plot(iters, self.losses[loss_type], 'g', label='train loss')
if loss_type == 'epoch':
# val_acc
plt.plot(iters, self.val_acc[loss_type], 'b', label='val acc')
# val_loss
plt.plot(iters, self.val_loss[loss_type], 'k', label='val loss')
plt.grid(True)
plt.xlabel(loss_type)
plt.ylabel('acc-loss')
plt.legend(loc="upper right")
plt.show()
#变量初始化
batch_size = 128
nb_classes = 10
nb_epoch = 20
# the data, shuffled and split between train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
#建立模型 使用Sequential()
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
#打印模型
model.summary()
#训练与评估
#编译模型
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
#创建一个实例history
history = LossHistory()
#迭代训练(注意这个地方要加入callbacks)
model.fit(X_train, Y_train,
batch_size=batch_size, nb_epoch=nb_epoch,
verbose=1,
validation_data=(X_test, Y_test),
callbacks=[history])
#模型评估
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
#绘制acc-loss曲线
history.loss_plot('epoch')
补充知识:keras中自定义验证集的性能评估(ROC,AUC)
在keras中自带的性能评估有准确性以及loss,当需要以auc作为评价验证集的好坏时,就得自己写个评价函数了:
from sklearn.metrics import roc_auc_score from keras import backend as K # AUC for a binary classifier def auc(y_true, y_pred): ptas = tf.stack([binary_PTA(y_true,y_pred,k) for k in np.linspace(0, 1, 1000)],axis=0) pfas = tf.stack([binary_PFA(y_true,y_pred,k) for k in np.linspace(0, 1, 1000)],axis=0) pfas = tf.concat([tf.ones((1,)) ,pfas],axis=0) binSizes = -(pfas[1:]-pfas[:-1]) s = ptas*binSizes return K.sum(s, axis=0) #------------------------------------------------------------------------------------ # PFA, prob false alert for binary classifier def binary_PFA(y_true, y_pred, threshold=K.variable(value=0.5)): y_pred = K.cast(y_pred >= threshold, 'float32') # N = total number of negative labels N = K.sum(1 - y_true) # FP = total number of false alerts, alerts from the negative class labels FP = K.sum(y_pred - y_pred * y_true) return FP/N #----------------------------------------------------------------------------------- # P_TA prob true alerts for binary classifier def binary_PTA(y_true, y_pred, threshold=K.variable(value=0.5)): y_pred = K.cast(y_pred >= threshold, 'float32') # P = total number of positive labels P = K.sum(y_true) # TP = total number of correct alerts, alerts from the positive class labels TP = K.sum(y_pred * y_true) return TP/P #接着在模型的compile中设置metrics #如下例子,我用的是RNN做分类
from keras.models import Sequential
from keras.layers import Dense, Dropout
import keras
from keras.layers import GRU
model = Sequential()
model.add(keras.layers.core.Masking(mask_value=0., input_shape=(max_lenth, max_features))) #masking用于变长序列输入
model.add(GRU(units=n_hidden_units,activation='selu',kernel_initializer='orthogonal', recurrent_initializer='orthogonal',
bias_initializer='zeros', kernel_regularizer=regularizers.l2(0.01), recurrent_regularizer=regularizers.l2(0.01),
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None,
bias_constraint=None, dropout=0.5, recurrent_dropout=0.0, implementation=1, return_sequences=False,
return_state=False, go_backwards=False, stateful=False, unroll=False))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=[auc]) #写入自定义评价函数
接下来就自己作预测了...
方法二:
from sklearn.metrics import roc_auc_score
import keras
class RocAucMetricCallback(keras.callbacks.Callback):
def __init__(self, predict_batch_size=1024, include_on_batch=False):
super(RocAucMetricCallback, self).__init__()
self.predict_batch_size=predict_batch_size
self.include_on_batch=include_on_batch
def on_batch_begin(self, batch, logs={}):
pass
def on_batch_end(self, batch, logs={}):
if(self.include_on_batch):
logs['roc_auc_val']=float('-inf')
if(self.validation_data):
logs['roc_auc_val']=roc_auc_score(self.validation_data[1],
self.model.predict(self.validation_data[0],
batch_size=self.predict_batch_size))
def on_train_begin(self, logs={}):
if not ('roc_auc_val' in self.params['metrics']):
self.params['metrics'].append('roc_auc_val')
def on_train_end(self, logs={}):
pass
def on_epoch_begin(self, epoch, logs={}):
pass
def on_epoch_end(self, epoch, logs={}):
logs['roc_auc_val']=float('-inf')
if(self.validation_data):
logs['roc_auc_val']=roc_auc_score(self.validation_data[1],
self.model.predict(self.validation_data[0],
batch_size=self.predict_batch_size))
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import GRU
import keras
from keras.callbacks import EarlyStopping
from sklearn.metrics import roc_auc_score
from keras import metrics
cb = [
my_callbacks.RocAucMetricCallback(), # include it before EarlyStopping!
EarlyStopping(monitor='roc_auc_val',patience=300, verbose=2,mode='max')
]
model = Sequential()
model.add(keras.layers.core.Masking(mask_value=0., input_shape=(max_lenth, max_features)))
# model.add(Embedding(input_dim=max_features+1, output_dim=64,mask_zero=True))
model.add(GRU(units=n_hidden_units,activation='selu',kernel_initializer='orthogonal', recurrent_initializer='orthogonal',
bias_initializer='zeros', kernel_regularizer=regularizers.l2(0.01), recurrent_regularizer=regularizers.l2(0.01),
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None,
bias_constraint=None, dropout=0.5, recurrent_dropout=0.0, implementation=1, return_sequences=False,
return_state=False, go_backwards=False, stateful=False, unroll=False)) #input_shape=(max_lenth, max_features),
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=[auc]) #这里就可以写其他评估标准
model.fit(x_train, y_train, batch_size=train_batch_size, epochs=training_iters, verbose=2,
callbacks=cb,validation_split=0.2,
shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
亲测有效!
以上这篇keras绘制acc和loss曲线图实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











