
小数据用csv,大数据用h5
结论1:几百KB以上的数据都用h5比较好
结论2:几KB的数据h5反而很慢
程序
import pandas as pd
import numpy as np
from wja.wja_tool import test_time as tt
from wja import wja_tool as tool
df = tool.generate_sampleDF(row, col)
tt().run()
df.to_csv('try.csv')
tt().end()
tt().run()
df.to_hdf('try.h5','df',mode='w')
tt().end()
tt().run()
df1 = pd.read_csv('try.csv')
tt().end()
tt().run()
df2 = pd.read_hdf('try.h5')
tt().end()
对比1:数据10*1
df = tool.generate_sampleDF(10,1)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:0.015 程序用时:0.9985 程序用时:0.009 程序用时:0.0369
对比2:数据100*10
df = tool.generate_sampleDF(100,10)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:0.017 程序用时:1.1016 程序用时:0.01 程序用时:0.013
对比3:数据1000*100
df = tool.generate_sampleDF(1000,100)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:0.2383 程序用时:1.0308 程序用时:0.0499 程序用时:0.016
对比4:数据10000*100
df = tool.generate_sampleDF(10000,100)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:2.0895 程序用时:1.0073 程序用时:0.4055 程序用时:0.0169
对比5:数据10000*1000
# csv保存 # hdf保存 # csv读取 # hdf读取 df = tool.generate_sampleDF(10000,1000)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:23.5693 程序用时:2.2057 程序用时:3.3697 程序用时:0.0619
补充知识:python:n个点m条边有权无向图
n个点:有个位置
m条边:两点之间存在m条边有权值
有权:每条边代表一个数值
无向:没有规定行进方向
规定:
1、两点之间的行进路线,最终权值为所经过的边的权值的最大值
2、两点之间走法不止一个,最终取最小值为最终走法
问:
两点之间的最终权值为多少
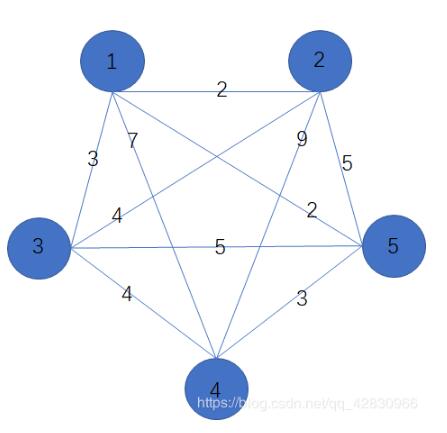
如上图,我们可以将其写为列表形式,前两位是从小到大的的两个点,最后一个代表权值,如
[1, 2, 2] 代表1和2之间的权值是2,以此类推
n,m = 5, 10
road = [[1, 2, 2], [1, 3, 3], [1, 4, 7], [1, 5, 2],
[2, 3, 4], [2, 4, 9], [2, 5, 5], [3, 4, 4],
[3, 5, 5], [4, 5, 3]]
def hold(list1, list2):
jiaoji = list(set(list1)&set(list2))
need = [i for i in set(list1+list2) if i not in jiaoji]
need.sort()
return need
def get(road):
option = {}
for i in range (m):
option[(road[i][0],road[i][1])] = [road[i][2]]
for i in range (m):
for j in range(i+1,m):
dot = hold(road[i][:2], road[j][:2])
if len(dot)==2:
if (dot[0],dot[1]) in option.keys():
option[(dot[0],dot[1])].append(max([road[i][2],road[j][2]]))
else:
option[(dot[0],dot[1])] = []
option[(dot[0],dot[1])].append(max([road[i][2],road[j][2]]))
road_new = []
for i in option.items():
road_new.append(list(i[0])+[min(i[1])])
if road==road_new:
print(road_new)
return road_new
return get(road_new)
输出结果
所有可能的走法如下,并且最后一位输出最短的权值路径。
例如 [2, 3, 3]:代表 从2走到3最短的权值路径是3,对应路径从图中可以到是2-1-3
例如 [3, 5, 3]:代表 从3走到5最短的权值路径是3,对应路径从图中可以到是3-1-5
[[1, 2, 2], [1, 3, 3], [1, 4, 3], [1, 5, 2], [2, 3, 3],
[2, 4, 3], [2, 5, 2], [3, 4, 3], [3, 5, 3], [4, 5, 3]]
以上这篇python:HDF和CSV存储优劣对比分析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











