
我就废话不多说了,大家还是直接看代码吧!
# encoding=utf-8
import numpy as np
import pandas as pd
# 长宽格式的转换
# 1
data = pd.read_csv('d:data/macrodata.csv')
print 'data:=\n', data
print 'data.to_records():=\n', data.to_records()
print 'data.year:=\n', data.year
print 'data.quarter:=\n', data.quarter
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter, name='date')
print 'periods:=\n', periods
data = pd.DataFrame(data.to_records(),
columns=pd.Index(['realgdp', 'infl', 'unemp'], name='item'),
index=periods.to_timestamp('D', 'end'))
print 'data:=\n', data
ldata = data.stack().reset_index().rename(columns={0: 'value'})
# print 'ldata:=\n', ldata
print 'ldata.get(\'realgdp\'):=\n', ldata.get('realgdp')
print 'ldata.get(\'unemp\'):=\n', ldata.get('unemp')
wdata = ldata.pivot('date', 'item', 'value')
print 'ldata:=\n', ldata
print 'wdata:=\n', wdata
# 2
print 'ldata[:10]:=\n', ldata[:10]
pivoted = ldata.pivot('date', 'item', 'value')
print 'pivoted:=\n', pivoted
print 'pivoted.head():=\n', pivoted.head()
print 'ldata:=\n', ldata
ldata['value2'] = np.random.randn(len(ldata))
print 'ldata[\'value2\']:=\n', ldata['value2']
print 'ldata[:10]:=\n', ldata[:10]
pivoted = ldata.pivot('date', 'item')
print 'pivoted:=\n', pivoted
print pivoted[:5]
print 'pivoted[\'value\'][:5]:=\n', pivoted['value'][:5]
print 'ldata:=\n', ldata
unstacked = ldata.set_index(['date', 'item']).unstack('item')
print 'unstacked:=\n', unstacked
print 'test'
补充知识:python使用_pandas_用stack和unstack进行行列重塑(key-value变宽表)
数据结构的重塑(reshape)
与数据库交互时常遇到堆叠格式(key-value)和宽表形式(dataframe)的转换,如:
堆叠格式:
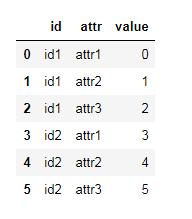
宽表形式dataframe:
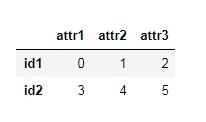
下面是相互转换的示例代码:
import pandas as pd
import numpy as np
# 常用的表格形式的数据结构
df = pd.DataFrame(np.arange(6).reshape((2,3)), index=['id1','id2'], columns=['attr1','attr2','attr3'])
print(df)
out:
attr1 attr2 attr3
id1 0 1 2
id2 3 4 5
# 宽表形式(dataframe)转变为堆叠形式(key-value)形式
# 数据库中常以该形式存储
df_key_value = df.stack().reset_index()
df_key_value.columns = ['id', 'attr', 'value']
print(df_key_value)
out:
id attr value
0 id1 attr1 0
1 id1 attr2 1
2 id1 attr3 2
3 id2 attr1 3
4 id2 attr2 4
5 id2 attr3 5
# 堆叠转换为宽表形式
# 用set_index创建层次化索引,在用unstack重塑
# unstack中作为旋转轴的变量(如attr),其值会作为列变量展开
df_key_value.set_index(['id','attr']).unstack('attr')
out:
value
attr attr1 attr2 attr3
id
id1 0 1 2
id2 3 4 5
# 多层索引转化为宽表
df_long = df_key_value.set_index(['id','attr']).unstack('attr')['value'].reset_index()
df_long
out:
attr id attr1 attr2 attr3
0 id1 0 1 2
1 id2 3 4 5
# 堆叠转换为宽表的快捷键---pivot
df_key_value.pivot('id','attr','value')
out:
attr attr1 attr2 attr3
id
id1 0 1 2
id2 3 4 5
以上这篇python 数据分析实现长宽格式的转换就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











