
一、问题描述
当Jupyter Notebook的输出内容很多时,为了屏幕可以显示更多的代码行,我需要将输出的内容进行折叠。
二、解决方法
1、鼠标操作
(1)鼠标左键双击输出单元格的左侧灰色区域。
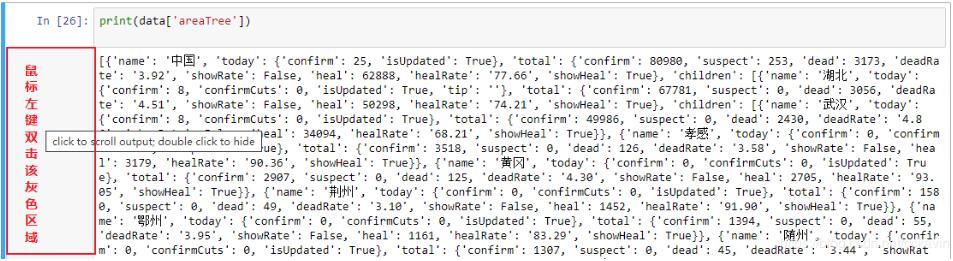
(2)展开:鼠标左键单机下方的灰色区域即可。如下图所示:

2、快捷键操作
(1)按Esc键

(2)按字母O

(3)展开:同上。
补充知识:Python 找出出现次数超过数组长度一半的元素实例
利用问题的普遍性和特殊性来求解,代码如下:
import unittest
from datetime import datetime
class GetFreqNumbersFromList(unittest.TestCase):
def setUp(self):
print("\n")
self.start_time = datetime.now()
print(f"{self._testMethodName} start: {self.start_time}")
def tearDown(self):
self.end_time = datetime.now()
print(f"{self._testMethodName} end: {self.end_time}")
exec_time = (self.end_time - self.start_time).microseconds
print(f"{self._testMethodName} exec_time: {exec_time}")
def normal_solution(self, _list, _debug=False):
"""
普遍性解法
利用字典记录每个元素出现的次数——然后找出元素出现次数超过数组长度一半的元素
普遍性解法针对任何次数的统计均适用而不光只是针对出现次数超过数组长度一半的情况
"""
_target = len(_list) // 2
_dict = {}
for _member in _list:
if _member not in _dict:
_dict.setdefault(_member, 1)
else:
_dict[_member] += 1
_ret = [_member for _member in _dict if _dict[_member] > _target]
if _debug:
print(_ret)
return _ret
def specific_solution(self, _list, _debug=False):
"""
特殊性解法
假设有两个元素出现的次数都超过数组长度一半就会得出两个元素出现的次数超出了数组长度的矛盾结果——所以超过数组长度一半的元素是唯一的
排序后在数组中间的一定是目标解
特殊性解法只能针对元素出现次数超过数组长度一半的情况
"""
_list.sort()
if _debug:
print(_list[len(_list) // 2])
return _list[len(_list) // 2]
def test_normal_solution(self):
actual_result = self.normal_solution([2,2,2,2,2,2,1,1,1,1,1], False)
self.assertEqual(actual_result[0], 2)
def test_specific_solution(self):
actual_result = self.specific_solution([2,2,2,2,2,2,1,1,1,1,1], False)
self.assertEqual(actual_result, 2)
if __name__ == "__main__":
# 找出出现次数超过数组长度一半的元素
suite = unittest.TestSuite()
suite.addTest(GetFreqNumbersFromList('test_normal_solution'))
suite.addTest(GetFreqNumbersFromList('test_specific_solution'))
runner = unittest.TextTestRunner()
runner.run(suite)
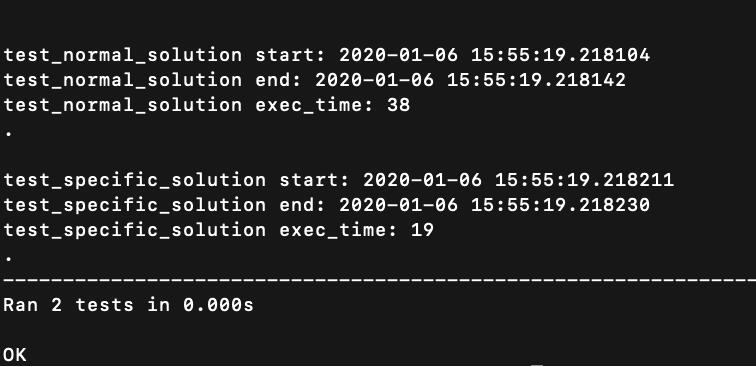
测试结果:
在一篇文章看到这个LeetCode上的问题,自己动手写写♪(・ω・)ノ
以上这篇Jupyter Notebook折叠输出的内容实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











