
Python实时数据采集-新型冠状病毒
源代码 来源:https://github.com/Programming-With-Love/2019-nCoV
疫情数据时间为:2020.2.1
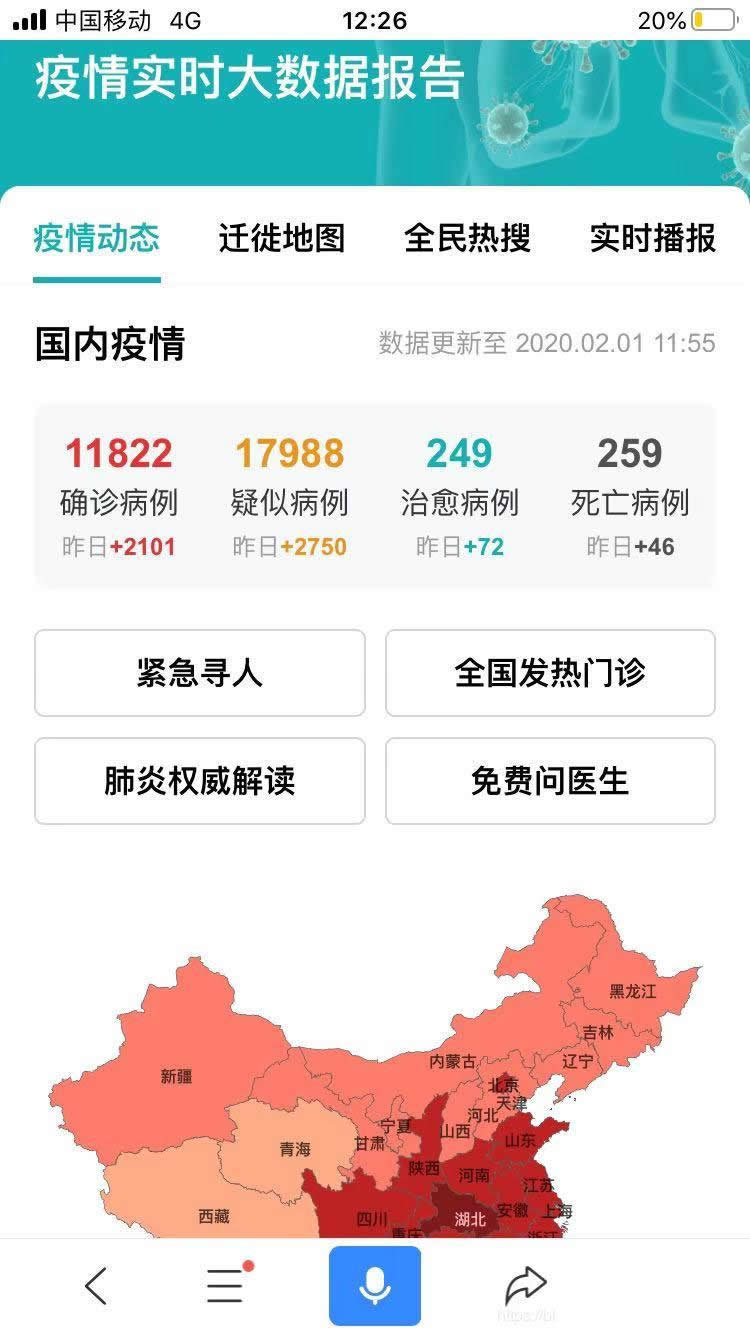
项目相关截图:
全国数据展示

国内数据展示

国外数据展示

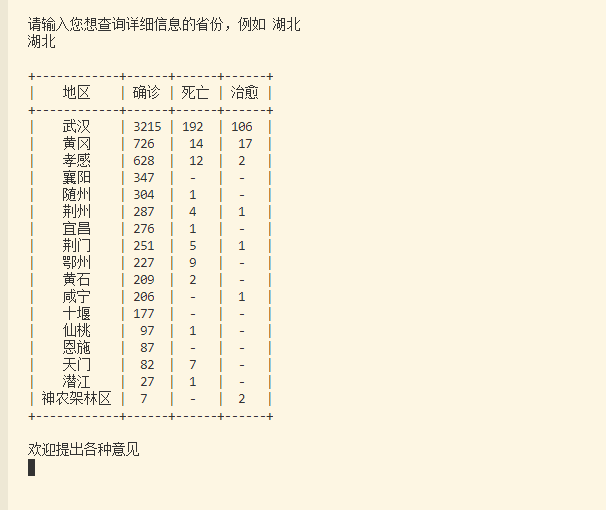
查看指定区域详细数据
源代码,注意安装所需模块(例如 pip install 模块名)
import requests
import re
from bs4 import BeautifulSoup
from time import sleep
import json
from prettytable import ALL
from prettytable import PrettyTable
hubei = {}
guangdong = {}
zhejiang = {}
beijing = {}
shanghai = {}
hunan = {}
anhui = {}
chongqing = {}
sichuan = {}
shandong = {}
guangxi = {}
fujian = {}
jiangsu = {}
henan = {}
hainan = {}
tianjin = {}
jiangxi = {}
shanxi1 = {} # 陕西
guizhou = {}
liaoning = {}
xianggang = {}
heilongjiang = {}
aomen = {}
xinjiang = {}
gansu = {}
yunnan = {}
taiwan = {}
shanxi2 = {} # 山西
jilin = {}
hebei = {}
ningxia = {}
neimenggu = {}
qinghai = {} # none
xizang = {} # none
provinces_idx = [hubei, guangdong, zhejiang, chongqing, hunan, anhui, beijing,
shanghai, henan, guangxi, shandong, jiangxi, jiangsu, sichuan,
liaoning, fujian, heilongjiang, hainan, tianjin, hebei, shanxi2,
yunnan, xianggang, shanxi1, guizhou, jilin, gansu, taiwan,
xinjiang, ningxia, aomen, neimenggu, qinghai, xizang]
map = {
'湖北':0, '广东':1, '浙江':2, '北京':3, '上海':4, '湖南':5, '安徽':6, '重庆':7,
'四川':8, '山东':9, '广西':10, '福建':11, '江苏':12, '河南':13, '海南':14,
'天津':15, '江西':16, '陕西':17, '贵州':18, '辽宁':19, '香港':20, '黑龙江':21,
'澳门':22, '新疆':23, '甘肃':24, '云南':25, '台湾':26, '山西':27, '吉林':28,
'河北':29, '宁夏':30, '内蒙古':31, '青海':32, '西藏':33
}
def getTime(text):
TitleTime = str(text)
TitleTime = re.findall('<span>(.*?)</span>', TitleTime)
return TitleTime[0]
def getAllCountry(text):
AllCountry = str(text)
AllCountry = AllCountry.replace("[<p class=\"confirmedNumber___3WrF5\"><span class=\"content___2hIPS\">", "")
AllCountry = AllCountry.replace("<span style=\"color: #4169e2\">", "")
AllCountry = re.sub("</span>", "", AllCountry)
AllCountry = AllCountry.replace("</p>]", "")
AllCountry = AllCountry.replace("<span style=\"color: rgb(65, 105, 226);\">", "")
AllCountry = re.sub("<span>", "", AllCountry)
AllCountry = re.sub("<p>", "", AllCountry)
AllCountry = re.sub("</p>", "", AllCountry)
return AllCountry
def query(province):
table = PrettyTable(['地区', '确诊', '死亡', '治愈'])
for (k, v) in province.items():
name = k
table.add_row([name, v[0] if v[0] != 0 else '-', v[1] if v[1] != 0 else '-', v[2] if v[2] != 0 else '-'])
if len(province.keys()) != 0:
print(table)
else:
print("暂无")
def getInfo(text):
text = str(text)
text = re.sub("<p class=\"descText___Ui3tV\">", "", text)
text = re.sub("</p>", "", text)
return text
def is_json(json_str):
try:
json.loads(json_str)
except ValueError:
return False
return True
def ff(str, num):
return str[:num] + str[num+1:]
def main():
url = "https://3g.dxy.cn/newh5/view/pneumonia"
try:
headers = {}
headers['user-agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' #http头大小写不敏感
headers['accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
headers['Connection'] = 'keep-alive'
headers['Upgrade-Insecure-Requests'] = '1'
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,'lxml')
table = PrettyTable(['地区', '确诊', '死亡', '治愈'])
table.hrules = ALL
#### 截至时间
# TitleTime = getTime(soup.select('.title___2d1_B'))
print()
# print(" ",TitleTime + "\n")
while True:
r = requests.get("https://service-f9fjwngp-1252021671.bj.apigw.tencentcs.com/release/pneumonia")
json_str = json.loads(r.text)
if json_str['error'] == 0:
break
print("==================================全国数据==================================")
print()
print(" 确诊 " + str(json_str['data']['statistics']['confirmedCount']) + " 例"
+ " " + "疑似 " + str(json_str['data']['statistics']['suspectedCount']) + " 例"
+ " " + "死亡" + str(json_str['data']['statistics']['deadCount']) + " 例"
+ " " + "治愈" + str(json_str['data']['statistics']['curedCount']) + " 例\n")
print("==================================相关情况==================================")
print()
print("传染源:" + json_str['data']['statistics']['infectSource'])
print("病毒:" + json_str['data']['statistics']['virus'])
print("传播途径:" + json_str['data']['statistics']['passWay'])
print(json_str['data']['statistics']['remark1'])
print(json_str['data']['statistics']['remark2'] + "\n")
print("==================================国内情况==================================")
print()
json_provinces = re.findall("{\"provinceName\":(.*?)]}", str(soup))
idx = 0
for province in json_provinces:
if is_json(province):
pass
else:
province = "{\"provinceName\":" + province + "]}"
province = json.loads(province)
province_name = province['provinceShortName'] if province['provinceShortName'] != 0 else '-'
confirmed = province['confirmedCount'] if province['confirmedCount'] != 0 else '-'
suspected = province['suspectedCount'] if province['suspectedCount'] != 0 else '-'
cured = province['curedCount'] if province['curedCount'] != 0 else '-'
dead = province['deadCount'] if province['deadCount'] != 0 else '-'
table.add_row([province_name, confirmed, dead, cured])
map[province_name] = idx
idx = idx + 1
for city in province['cities']:
provinces_idx[map[province_name]][city['cityName']] = [city['confirmedCount'], city['deadCount'], city['curedCount']]
print(table)
print()
print("==================================国外情况==================================")
print()
json_provinces = str(re.findall("\"id\":949(.*?)]}", str(soup)))
json_provinces = json_provinces[:1] + "{\"id\":949" + json_provinces[2:]
json_provinces = json_provinces[:len(json_provinces) - 2] + json_provinces[len(json_provinces) - 1:]
provinces = json.loads(json_provinces)
table = PrettyTable(['地区', '确诊', '死亡', '治愈'])
for province in provinces:
confirmed = province['confirmedCount'] if province['confirmedCount'] != 0 else '-'
dead = province['deadCount'] if province['deadCount'] != 0 else '-'
cured = province['curedCount'] if province['curedCount'] != 0 else '-'
table.add_row([province['provinceName'], confirmed, dead, cured])
print(table)
print()
print("==================================最新消息==================================")
print()
idx = 0
for news in json_str['data']['timeline']:
if idx == 5:
break
print(news['pubDateStr'] + " " + news['title'])
idx = idx + 1
print()
key = input("请输入您想查询详细信息的省份,例如 湖北\n")
print()
if key in map.keys():
query(provinces_idx[map[key]])
else:
print("暂无相关信息")
print("\n欢迎提出各种意见")
except:
print("连接失败")
if __name__ == '__main__':
main()
sleep(30)
以上就是Python实时数据采集-新型冠状病毒的详细内容,大家出门要做好安全措施,感谢对脚本之家的支持。











