
工作中,我们经常会遇到数据异常,比如说浏览量突增猛降,交易量突增猛降,但是这些数据又不是符合正太分布的,如果用几倍西格玛就不合适,那么我们如何来判断这些变化是否在合理的范围呢?
小白查阅一些资料后,发现可以用箱形图,具体描述如下:
箱形图(英文:Box plot),又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。箱形图最大的优点就是不受异常值的影响,能够准确稳定地描绘出数据的离散分布情况,同时也利于数据的清洗。
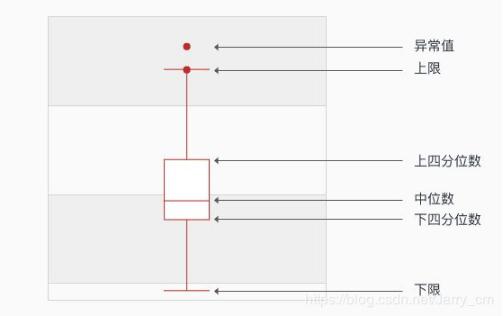
异常值可以设置为上四分位数的1.25倍,也可以设置为1.5倍,具体的要通过实验可得。
1、下四分位数Q1
(1)确定四分位数的位置。Qi所在位置=i(n+1)/4,其中i=1,2,3。n表示序列中包含的项数。
(2)根据位置,计算相应的四分位数。
例中:Q1所在的位置=(14+1)/4=3.75,Q1=0.25×第三项+0.75×第四项=0.25×17+0.75×19=18.5;
2、中位数(第二个四分位数)Q2中位数,即一组数由小到大排列处于中间位置的数。若序列数为偶数个,该组的中位数为中间两个数的平均数。
例中:Q2所在的位置=2(14+1)/4=7.5,Q2=0.5×第七项+0.5×第八项=0.5×25+0.5×28=26.5
3、上四分位数Q3计算方法同下四分位数。
例中:Q3所在的位置=3(14+1)/4=11.25,Q3=0.75×第十一项+0.25×第十二项=0.75×34+0.25×35=34.25。
4、上限上限是非异常范围内的最大值。
首先要知道什么是四分位距如何计算的?四分位距IQR=Q3-Q1,那么上限=Q3+1.5IQR5、下限下限是非异常范围内的最小值。下限=Q1-1.5IQR
我这里是使用上四分位数的1.5倍作为上限,下四分位数的1.5倍作为下限。
这里是拿历史一个月每天的产量和间夜量作为参考,统计出历史的箱线图的各个指标,然后将要比较的数据,来进行循环判断,若超过上限/下限那么抛出1和0.
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 30 10:52:37 2019
@author: chen_lib
"""
import pandas as pd
catering_sale = 'D:/Users/chen_lib/Desktop/ceshi.csv' #读取历史数据
datax = pd.read_csv(catering_sale) #读取数据
#取出不是昨天的数据
data = datax.loc[datax['orderdate'] != datetime][:]
'''
import time
## yyyy-mm-dd格式
print (time.strftime("%Y-%m-%d"))
'''
#时间减一天
import datetime
datetime = (datetime.datetime.now()+datetime.timedelta(days=-1)).strftime("%Y-%m-%d")
#保存基本统计量,将常见的统计信息保存为数据框
statistics = data.describe()
#添加行标签 计算出每个指标的上线下线和四分位间距
statistics.loc['IQR'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
statistics.loc['UP'] = statistics.loc['75%'] + 1.5*statistics.loc['IQR'] #上限
statistics.loc['DAWN'] = statistics.loc['25%'] - 1.5*statistics.loc['IQR']#下限
#取出data的列名
columns = data.columns.values.tolist()
'''取出要比较的数值,放在统计信息表'''
a = data.loc[data['orderdate'] == datetime][columns[1]]#取出第一列
b = data.loc[data['orderdate'] == datetime][columns[2]]#取出第二列
statistics.loc['res'] = [a[1],b[1]]#取出需要比较的当天的数据 放入统计信息中
'''循环取出结果是否满足要求'''
ret = []
for i in range(2):
res = statistics.loc['res'][i]
max = statistics.loc['UP'][columns[i+1]]#最大值
min = statistics.loc['DAWN'][columns[i+1]]#最小值
'''
#重建三个值的索引,以便比较大小
res.index = ['ordernum']
max.index = max['ordernum']
min.index = min['ordernum']
#判断异常值,若大于最大值或者小于最小值则抛出结果为1
'''
result1 = res>max
result2 = res<min
if result1 =='False' or result2 == 'False':
ret.append([columns[i+1],1])
else:
ret.append([columns[i+1],0])
df = pd.DataFrame(ret)
#将文件写入excel表中
df.to_excel("d:/Users/chen_lib/Desktop/ceshi.xlsx",sheet_name="total",index=False,header=False)
以上这篇Python实现非正太分布的异常值检测方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











