
这篇文章主要介绍了如何基于Python批量下载音乐,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
音乐是生活的调剂品,目前很多的音乐只能播放不能下载。生为技术员的我们,怎么甘心呢?
知识点:
开发环境:
第三方库:
网页分析
目标站点:http://music.taihe.com/search?key=%E9%99%88%E7%B2%92
分析音乐的真实地址
选择一首歌 以陈粒的走马为例
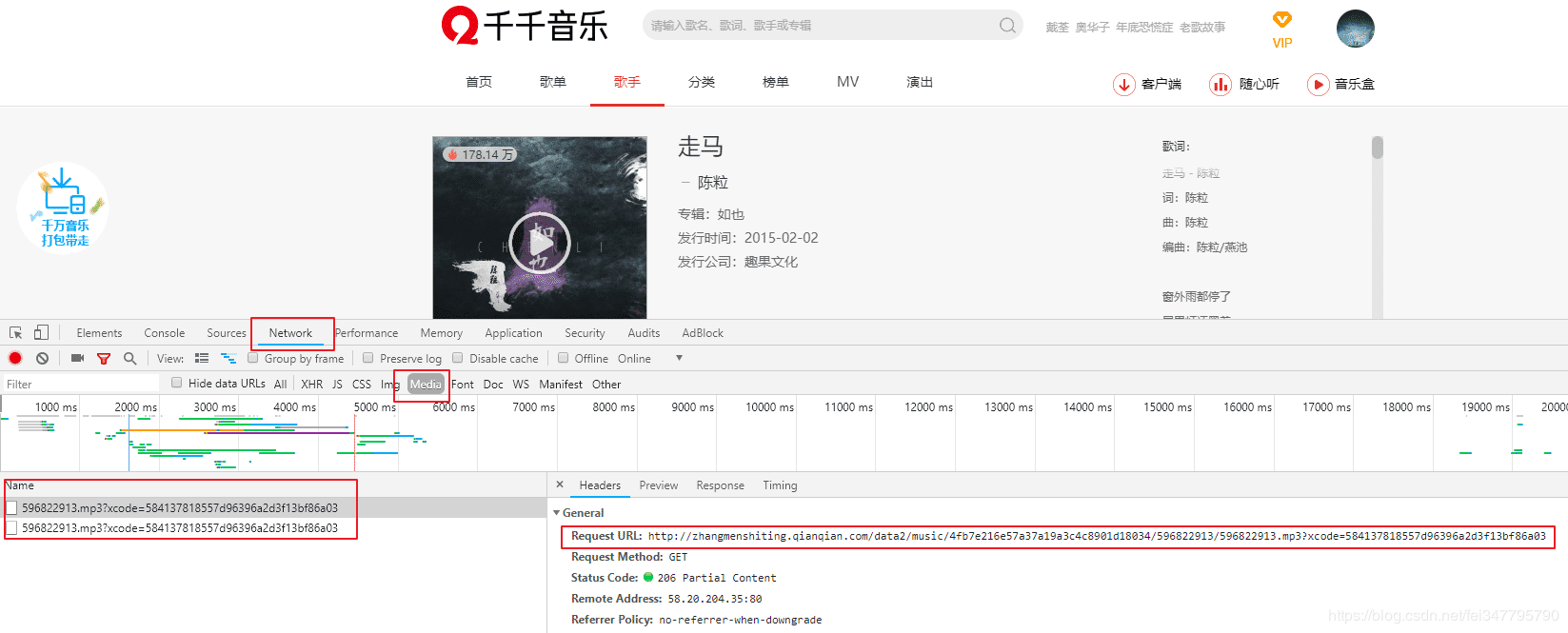
打开开发者工具,选择network -> media -> 刷新网页就能获取到音乐的真实地址
但是得到的地址在查看源码中是读取不到的,肯定是百度音乐对其进行了隐藏。这种时候一般会有两种情况。第一种是使用了 JavaScript 对请求连接进行了拼接或加密,第二种是数据被隐藏了。由于我们不清楚是出现了那种情况。所以我们只能慢慢的去分析请求的数据。
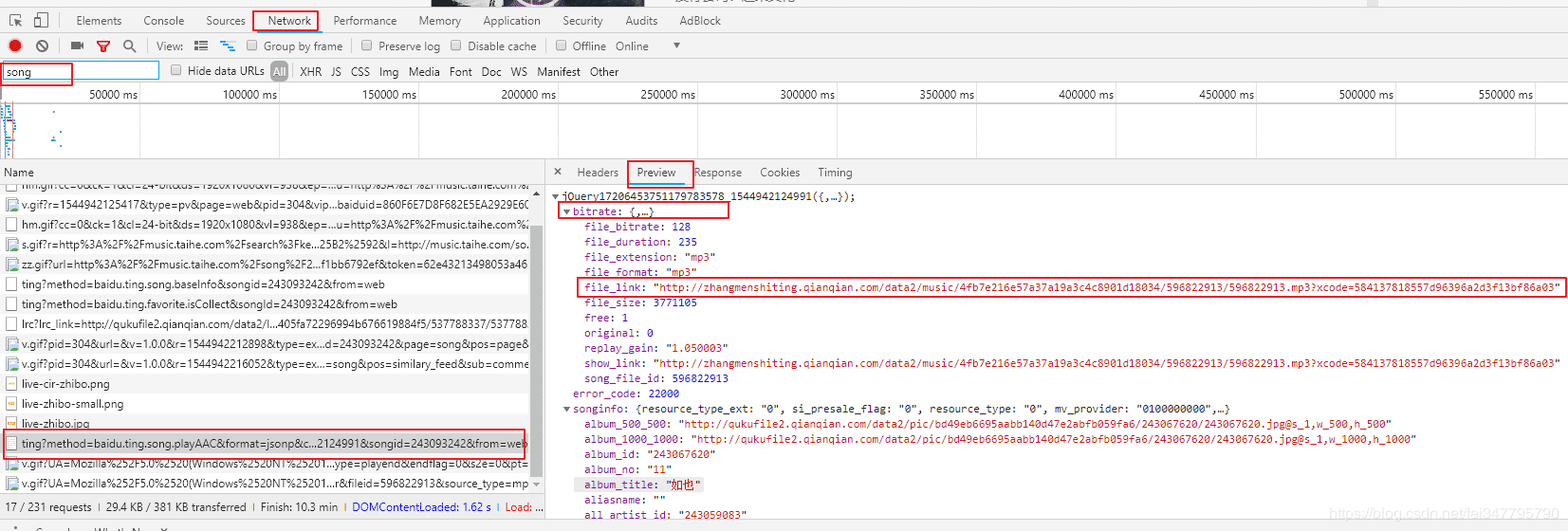
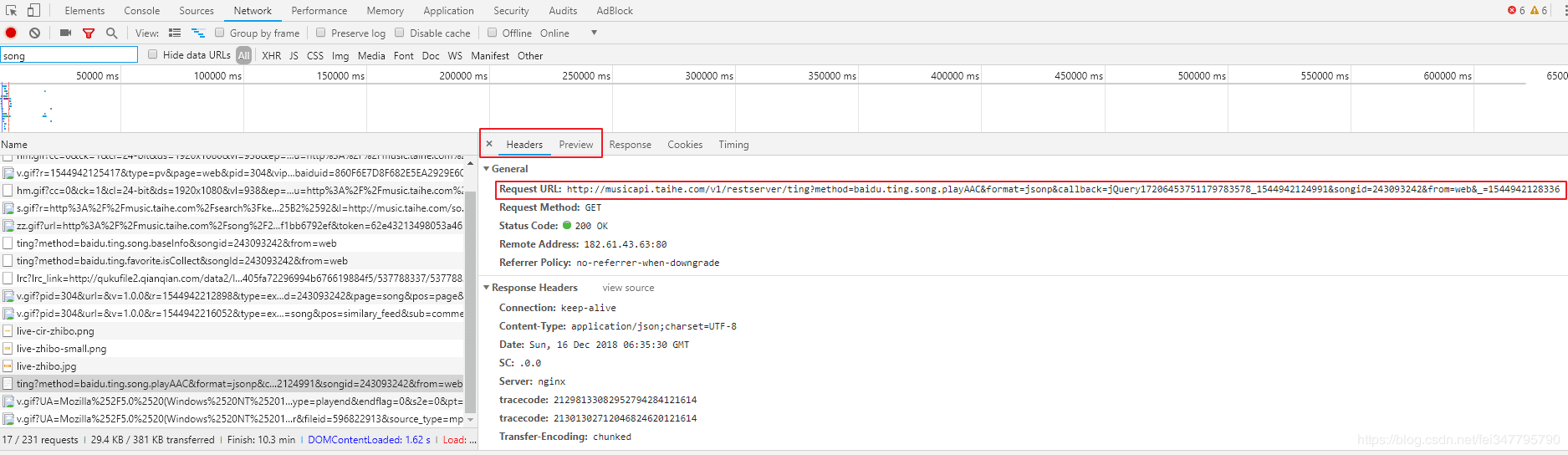
经过分析我们可以看到真实的音乐地址是存在于这个API里面http://musicapi.taihe.com/v1/restserver/ting?method=baidu.ting.song.playAAC&format=jsonp&callback=jQuery17206453751179783578_1544942124991&songid=243093242&from=web&_=1544942128336
并且我们请求这个 API 返回的是一个 json 数据(也就是python的字典数据类型)。只要我们使用字典的规则就能将我们的所有数据给提取到。
url拼接 获取所有数据
前面我们得到了音乐的真实地址,接下来我们就是分析真实地址的 url ,以期待得到下载所有音乐的诀窍。
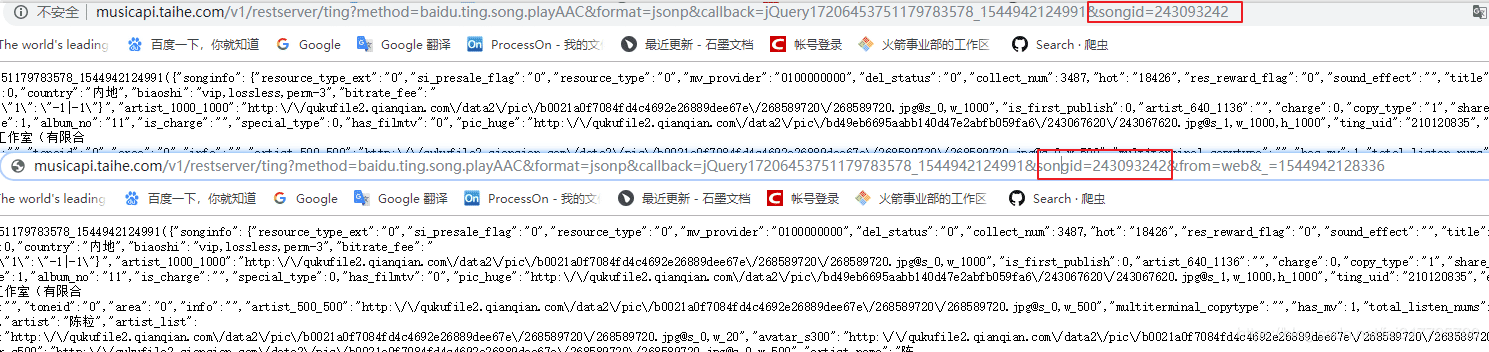

仔细分析一下 url 就可以发现,?后面的from参数与_即使不存在也不影响数据的请求。
并且后面的参数中的songid其实就是歌曲的唯一id,from参数其实就是表明从哪个平台过来的
所以等一下我们下载音乐时,只要批量获取到歌曲的songid就能将所有的歌曲给全部下载下来了。
批量获取singid
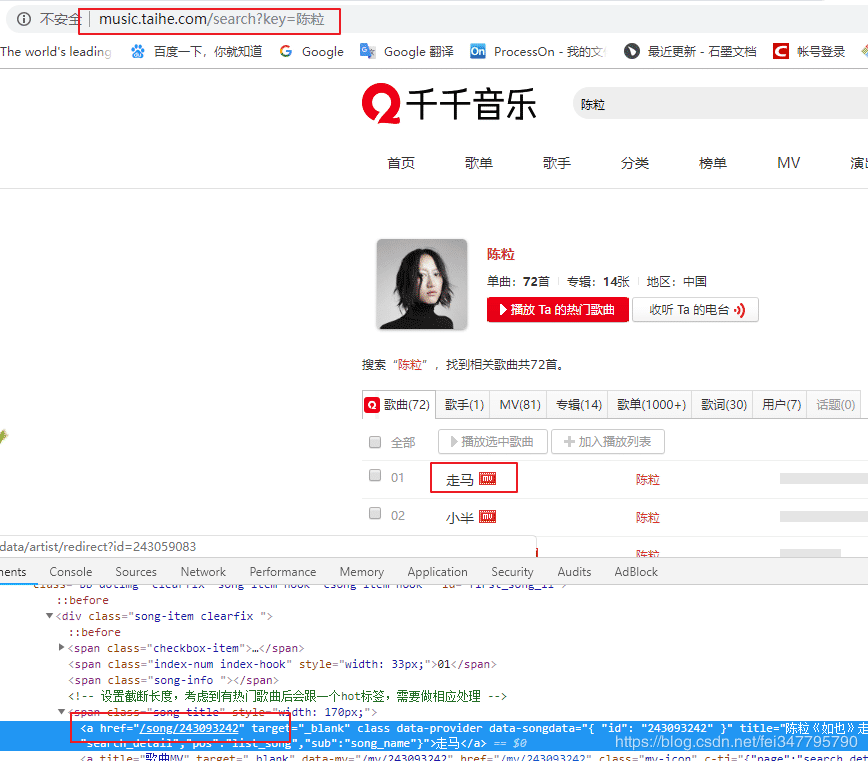
使用开发者工具,查看网页源码就能查看到songid的位置,如果我们分析一个歌手页面的url你会发现同样可以构造。
到此,整个网页分析就结束了。
实现效果
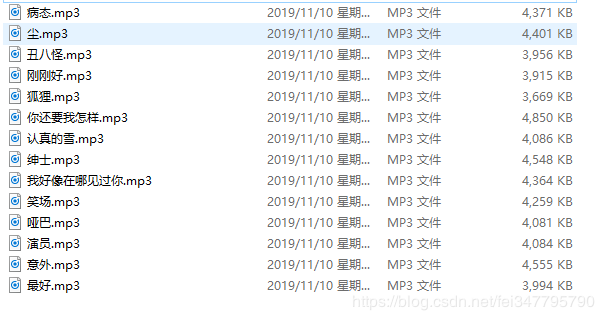
完整代码
import re
import requests
def get_songid():
"""获取音乐的songid"""
url = 'http://music.taihe.com/artist/2517'
response = requests.get(url=url)
html = response.text
sids = re.findall(r'href="/song/(\d+)" rel="external nofollow" ', html)
return sids
def get_music_url(songid):
"""获取下载链接"""
api_url = f'http://musicapi.taihe.com/v1/restserver/ting?method=baidu.ting.song.playAAC&format=jsonp&songid={songid}&from=web'
response = requests.get(api_url.format(songid=songid))
data = response.json()
print(data)
try:
music_name = data['songinfo']['title']
music_url = data['bitrate']['file_link']
return music_name, music_url
except Exception as e:
print(e)
def download_music(music_name, music_url):
"""下载音乐"""
response = requests.get(music_url)
content = response.content
save_file(music_name+'.mp3', content)
def save_file(filename, content):
"""保存音乐"""
with open(file=filename, mode="wb") as f:
f.write(content)
if __name__ == "__main__":
for song_id in get_songid():
music_name, music_url = get_music_url(song_id)
download_music(music_name, music_url)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。









