
python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'的解决方法:
1.原因是官网的是python2语法写的,看官手动把官网的HTMLTestRunner.py改成python3的语法:
参考:http://bbs.chinaunix.net/thread-4154743-1-1.html
下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
修改后下载地址:HTMLTestRunner_jb51.rar (懒人直接下载吧)
2.修改汇总:
第94行,将import StringIO修改成import io
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
第766行,将uo = o.decode('latin-1')修改成uo = e
第775行,将ue = e.decode('latin-1')修改成ue = e
第631行,将print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime)修改成print(sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
在Python3.4下使用HTMLTestRunner,开始时,引入HTMLTestRunner模块报错。
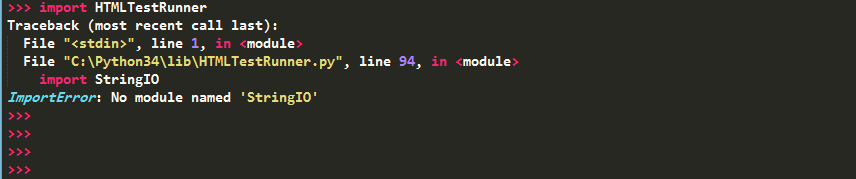
在HTMLTestRunner的94行中,是使用的StringIO,但是Python3中,已经没有StringIO了。取而代之的是io.StringIO。所以将此行修改成import io

在HTMLTestRunner的539行中,self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
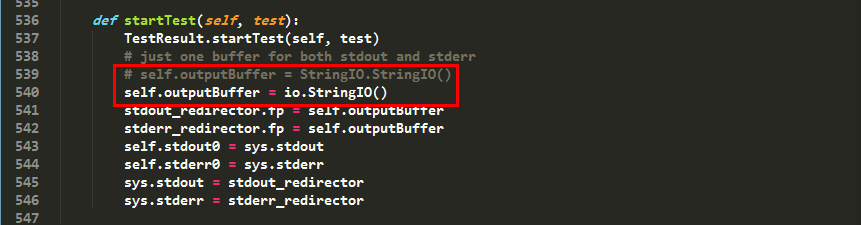
修改以后,成功引入模块了

执行脚本代码:
# -*- coding: utf-8 -*-
#引入webdriver和unittest所需要的包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
#引入HTMLTestRunner包
import HTMLTestRunner
class Baidu(unittest.TestCase):
#初始化设置
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
#百度搜索用例
def test_baidu(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("Selenium Webdriver")
driver.find_element_by_id("su").click()
time.sleep(2)
driver.close()
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
#定义一个测试容器
test = unittest.TestSuite()
#将测试用例,加入到测试容器中
test.addTest(Baidu("test_baidu"))
#定义个报告存放的路径,支持相对路径
file_path = "F:\\RobotTest\\result.html"
file_result= open(file_path, 'wb')
#定义测试报告
runner = HTMLTestRunner.HTMLTestRunner(stream = file_result, title = u"百度搜索测试报告", description = u"用例执行情况")
#运行测试用例
runner.run(test)
file_result.close()
运行测试脚本后,发现报错:
File "C:\Python34\lib\HTMLTestRunner.py", line 642, in sortResult
if not rmap.has_key(cls):
所以前往642行修改代码:

运行后继续报错:
AttributeError: 'str' object has no attribute 'decode'
前往766, 772行继续修改(注意:766行是uo而772行是ue,当时眼瞎,没有注意到这些,以为是一样的,导致报了一些莫名其妙的错误,折腾的半天):
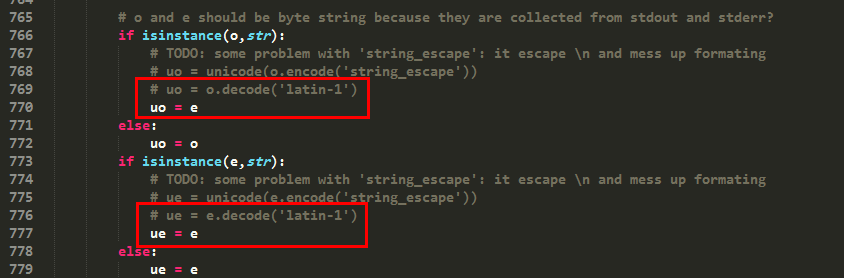
修改后运行,发现又报错:
File "C:\Python34\lib\HTMLTestRunner.py", line 631, in run
print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime)
TypeError: unsupported operand type(s) for >>: 'builtin_function_or_method' and '_io.TextIOWrapper'
前往631查看,发现整个程序中,唯一一个print:
print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime
这个是2.x的写法,咱们修改成3.x的print,修改如下:
print(sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。











