
本实例的实现逻辑是,应用selenium UI自动化登录百度盘,读取存储百度分享地址和提取码的txt文档,打开百度盘分享地址,填入提取码,然后保存到指定的目录中
全部代码如下:
# -*-coding:utf8-*-
# encoding:utf-8
import time
from selenium import webdriver
browser = webdriver.Chrome()
def loginphont():
browser.get("https://pan.baidu.com/")#打开链接
browser.maximize_window()
browser.find_element_by_id("TANGRAM__PSP_4__footerULoginBtn").click()
browser.find_element_by_id("TANGRAM__PSP_4__userName").send_keys("百度盘账号")
browser.find_element_by_id("TANGRAM__PSP_4__password").send_keys("百度盘密码")
browser.find_element_by_id("TANGRAM__PSP_4__submit").click()
time.sleep(3)
browser.find_element_by_id("TANGRAM__23__button_send_mobile").click()#发送验证码
time.sleep(20)
loginphont()
def keep():
for line in open('C:\\Users\\Beckham\\Desktop\\python\\1.txt'):#循环读取百度地址和提取码
address = line[0:47]#分离出百度盘地址
code = line[47:51]#分割出提取码
browser.get(address)#打开链接
browser.find_element_by_id("ksrmwk1v").send_keys(code)#输入提取码
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'提取文件')]").click()
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'保存到网盘')]").click()
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'存储文件目录')]").click()
time.sleep(2)
browser.find_element_by_xpath("//span[contains(text(),'确定')]").click()
time.sleep(5)
keep()
def over():
print("game over")
over()
百度盘资源的链接和提取码的爬取来源请参考这一实例:https://www.jb51.net/article/168449.htm
爬取后生成的txt文档如下图
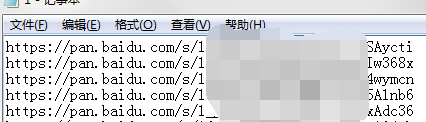
每一条数据的后4位为提取码,其余前面的内容为百度分享链接,所以有了下面的步骤,分离出分享地址和提取码
for line in open('C:\\Users\\Beckham\\Desktop\\python\\1.txt'):#循环读取百度地址和提取码
address = line[0:47]#分离出百度盘地址
code = line[47:51]#分割出提取码
browser.get(address)#打开链接
过程,步骤都相对简单,就不用每一步都讲解拉
以上所述是小编给大家介绍的python自动保存百度盘资源到百度盘中的实例代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!











