
一、什么是决策树(decision tree)——机器学习中的一个重要的分类算法
决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点
根据天气情况决定出游与否的案例
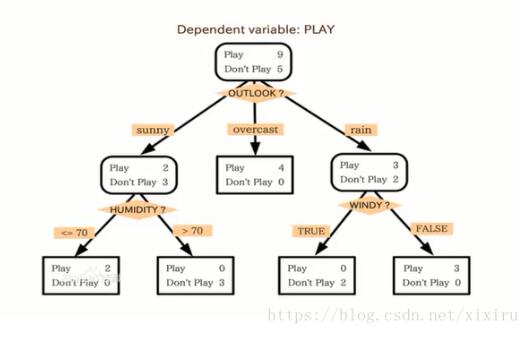
二、决策树算法构建
2.1决策树的核心思路
特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止声场。
剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
2.2 熵的概念:度量信息的方式
实现决策树的算法包括ID3、C4.5算法等。常见的ID3核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要大量的信息====>信息量的度量就等于不确定性的 多少。也就是说变量的不确定性越大,熵就越大
信息熵的计算公司
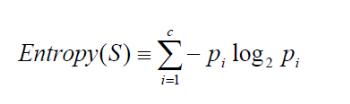
S为所有事件集合,p为发生概率,c为特征总数。
信息增益(information gain)是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算如下:
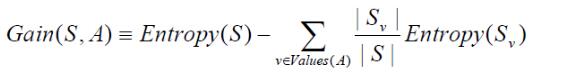
其中,第二项为属性A对S划分的期望信息。
三、IDE3决策树的Python实现
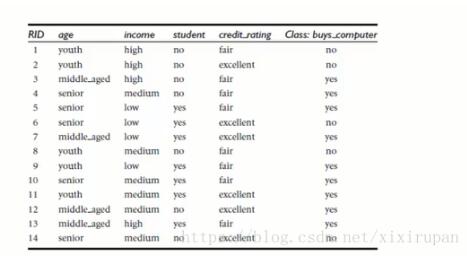
以下面这个不同年龄段的人买电脑的情况为例子建模型算法
'''
Created on 2018年7月5日
使用python内的科学计算的库实现利用决策树解决问题
@author: lenovo
'''
#coding:utf-8
from sklearn.feature_extraction import DictVectorizer
#数据存储的格式 python自带不需要安装
import csv
#预处理的包
from sklearn import preprocessing
from sklearn.externals.six import StringIO
from sklearn.tree import tree
from sklearn.tree import export_graphviz
'''
文件保存格式需要是utf-8
window中的目录形式需要是左斜杠 F:/AA_BigData/test_data/test1.csv
excel表格存储成csv格式并且是utf-8格式的编码
'''
'''
决策树数据源读取
scklearn要求的数据类型 特征值属性必须是数值型的
需要对数据进行预处理
'''
#装特征的值
featureList=[]
#装类别的词
labelList=[]
with open("F:/AA_BigData/test_data/decision_tree.csv", "r",encoding="utf-8") as csvfile:
decision =csv.reader(csvfile)
headers =[]
row =1
for item in decision:
if row==1:
row=row+1
for head in item:
headers.append(head)
else:
itemDict={}
labelList.append(item[len(item)-1])
for num in range(1,len(item)-1):
# print(item[num])
itemDict[headers[num]]=item[num]
featureList.append(itemDict)
print(headers)
print(labelList)
print(featureList)
'''
将原始数据转换成包含有字典的List
将建好的包含字典的list用DictVectorizer对象转换成0-1矩阵
'''
vec =DictVectorizer()
dumyX =vec.fit_transform(featureList).toarray();
#对于类别使用同样的方法
lb =preprocessing.LabelBinarizer()
dumyY=lb.fit_transform(labelList)
print(dumyY)
'''
1.构建分类器——决策树模型
2.使用数据训练决策树模型
'''
clf =tree.DecisionTreeClassifier(criterion="entropy")
clf.fit(dumyX,dumyY)
print(str(clf))
'''
1.将生成的分类器转换成dot格式的 数据
2.在命令行中dot -Tpdf iris.dot -o output.pdf将dot文件转换成pdf图的文件
'''
#视频上讲的不适用python3.5
with open("F:/AA_BigData/test_data/decisiontree.dot", "w") as wFile:
export_graphviz(clf,out_file=wFile,feature_names=vec.get_feature_names())
Graphviz对决策树的可视化

以上这篇Python实现决策树并且使用Graphviz可视化的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。










