
Django分页功能的实现
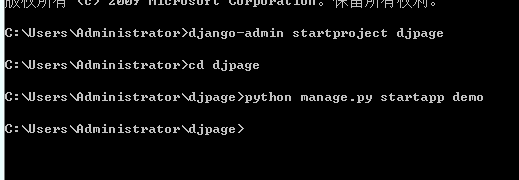
打开命令行窗口,创建Django工程,使用以下命令:
django-admin startproject djpage
cd djpage
python manage.py startapp demo
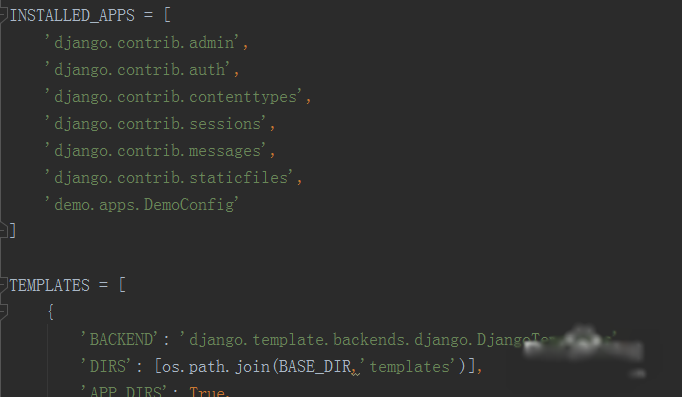
使用PyCharm打开工程,在工程的同名文件夹的settings.py文件,注册应用,添加模板路径,修改部分的settings.py内容如下:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'demo.apps.DemoConfig'
]
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR,'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
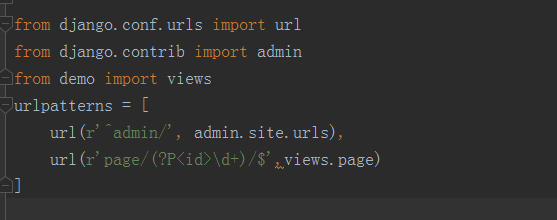
在工程同名文件的urls.py文件,添加到应用的视图的路由
from django.conf.urls import url from django.contrib import admin from demo import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'page/(?P<id>\d+)/$',views.page) ]
在应用的视图views.py文件,编写处理请求函数,实现分页显示一个列表的内容,这里列表也可以是查询集
from django.shortcuts import render
from django.core.paginator import Paginator
# Create your views here.
def page(request,id):
hello_list = [{'title':'hello'},{'title':'world'},
{'title':'hello1'},{'title':'world1'},
{'title':'hello2'},{'title':'world2'},
{'title':'hello3'},{'title':'world3'},
{'title':'hello4'},{'title':'world4'}]
pag = Paginator(hello_list, 2)
page = pag.page(int(id))
return render(request,template_name='home.html', context={'page': page})
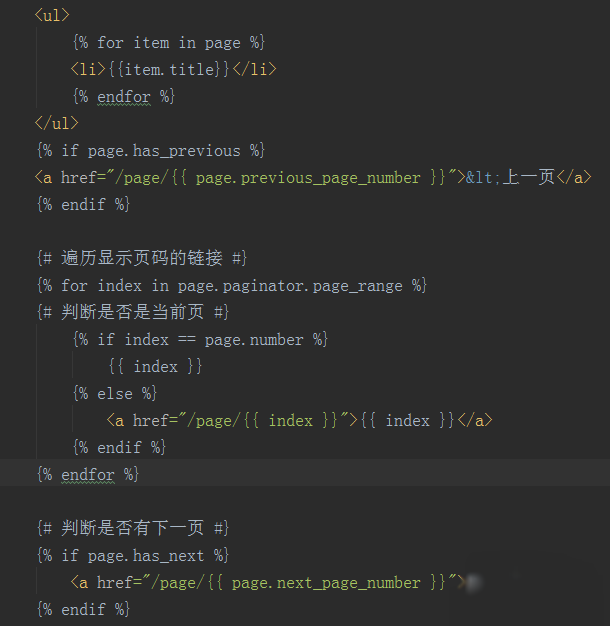
在工程根目录新建templates文件夹,并创建一个home.html文件,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
{% for item in page %}
<li>{{item.title}}</li>
{% endfor %}
</ul>
{% if page.has_previous %}
<a href="/page/{{ page.previous_page_number }}" rel="external nofollow" rel="external nofollow" ><上一页</a>
{% endif %}
{# 遍历显示页码的链接 #}
{% for index in page.paginator.page_range %}
{# 判断是否是当前页 #}
{% if index == page.number %}
{{ index }}
{% else %}
<a href="/page/{{ index }}" rel="external nofollow" rel="external nofollow" >{{ index }}</a>
{% endif %}
{% endfor %}
{# 判断是否有下一页 #}
{% if page.has_next %}
<a href="/page/{{ page.next_page_number }}" rel="external nofollow" rel="external nofollow" >下一页></a>
{% endif %}
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
{% for item in page %}
<li>{{item.title}}</li>
{% endfor %}
</ul>
{% if page.has_previous %}
<a href="/page/{{ page.previous_page_number }}" rel="external nofollow" rel="external nofollow" ><上一页</a>
{% endif %}
{# 遍历显示页码的链接 #}
{% for index in page.paginator.page_range %}
{# 判断是否是当前页 #}
{% if index == page.number %}
{{ index }}
{% else %}
<a href="/page/{{ index }}" rel="external nofollow" rel="external nofollow" >{{ index }}</a>
{% endif %}
{% endfor %}
{# 判断是否有下一页 #}
{% if page.has_next %}
<a href="/page/{{ page.next_page_number }}" rel="external nofollow" rel="external nofollow" >下一页></a>
{% endif %}
</body>
</html>
page.paginator.page_range是页面总数
运行django服务器
python manage.py runserver
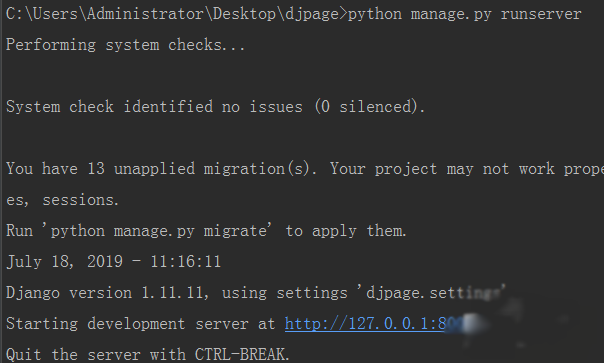
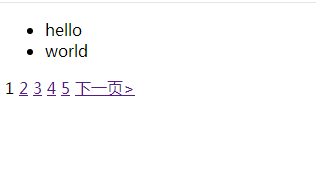
打开网页,输入
http://127.0.0.1:8000/page/1
显示效果图如下,分页成功
知识点扩展:
自定义分页的实例代码:
def book(request):
# 从URL取参数(访问的页码)
page_num = request.GET.get("page")
try:
# 将取出的page转换为int类型
page_num = int(page_num)
except Exception as e:
# 当输入的页码不是正经数字的时候 默认返回第一页的数据
page_num = 1
# 数据库总数据是多少条
total_count = models.Book.objects.all().count()
# 每一页显示多少条数据
per_page = 10
# 总共需要多少页码来展示
total_page, m = divmod(total_count, per_page)
if m:
total_page += 1
# 如果输入的页码数超过了最大的页码数,默认返回最后一页
if page_num > total_page:
page_num = total_page
# 定义两个变量从哪里开始到哪里结束
data_start = (page_num - 1) * 10
data_end = page_num * 10
# 页面上总共展示多少页码
max_page = 11
if total_page < max_page:
max_page = total_page
# 把从URL中获取的page_num 当做是显示页面的中间值, 那么展示的便是当前page_num 的前五页和后后五页
half_max_page = max_page // 2
# 根据展示的总页码算出页面上展示的页码从哪儿开始
page_start = page_num - half_max_page
# 根据展示的总页码算出页面上展示的页码到哪儿结束
page_end = page_num + half_max_page
# 如果当前页减一半 比1还小, 不然页面上会显示负数的页码
if page_start <= 1:
page_start = 1
page_end = max_page
# 如果 当前页 加 一半 比总页码数还大, 不然页面上会显示比总页码还大的多余页码
if page_end >= total_page:
page_end = total_page
page_start = total_page - max_page + 1
# 从数据库取值, 并按照起始数据到结束数据展示
all_book = models.Book.objects.all()[data_start:data_end]
# 自己拼接分页的HTML代码
html_str_list = []
# # 加上首页
html_str_list.append('<li><a href="/book/?page=1" rel="external nofollow" >首页</a></li>')
# 断一下 如果是第一页,就没有上一页
if page_num <= 1:
html_str_list.append('<li class="disabled"><a href="#" rel="external nofollow" rel="external nofollow" ><span aria-hidden="true">«</span></a></li>')
else:
# 不是第一页,就加一个上一页的标签
html_str_list.append('<li><a href="/book/?page={}" rel="external nofollow" rel="external nofollow" rel="external nofollow" ><span aria-hidden="true">«</span></a></li>'.format(page_num - 1))
for i in range(page_start, page_end + 1):
# 如果是当前页就加一个active样式类
if i == page_num:
tmp = '<li class="active"><a href="/book/?page={0}" rel="external nofollow" rel="external nofollow" >{0}</a></li>'.format(i)
else:
tmp = '<li><a href="/book/?page={0}" rel="external nofollow" rel="external nofollow" >{0}</a></li>'.format(i)
html_str_list.append(tmp)
# 判断,如果是最后一页,就没有下一页
if page_num >= total_page:
html_str_list.append('<li class="disabled"><a href="#" rel="external nofollow" rel="external nofollow" ><span aria-hidden="true">»</span></a></li>')
else:
# 不是最后一页, 就加一个下一页标签
html_str_list.append('<li><a href="/book/?page={}" rel="external nofollow" rel="external nofollow" rel="external nofollow" ><span aria-hidden="true">»</span></a></li>'.format(page_num + 1))
# 加上尾页
html_str_list.append('<li><a href="/book/?page={}" rel="external nofollow" rel="external nofollow" rel="external nofollow" >尾页</a></li>'.format(total_page))
page_html = "".join(html_str_list)
return render(request, "book.html", {"all_book":all_book, "page_html":page_html})











