
最近也是学习了一些爬虫方面的知识。以我自己的理解,通常我们用浏览器查看网页时,是通过浏览器向服务器发送请求,然后服务器响应以后返回一些代码数据,再经过浏览器解析后呈现出来。而爬虫则是通过程序向服务器发送请求,并且将服务器返回的信息,通过一些处理后,就能得到我们想要的数据了。
以下是前段时间我用python写的一个爬取TX新闻标题及其网址的一个简单爬虫:
首先需要用到python中requests(方便全面的http请求库)和 BeautifulSoup(html解析库)。
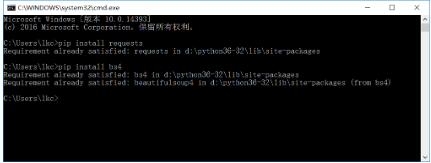
通过pip来安装这两个库,命令分别是:pip install requests 和 pip install bs4 (如下图)
先放上完整的代码
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = "http://news.qq.com/"
# 请求腾讯新闻的URL,获取其text文本
wbdata = requests.get(url).text
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata,'lxml')
# 从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles = soup.select("div.text > em.f14 > a.linkto")
# 对返回的列表进行遍历
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
print(data)
首先引入上述两个库
import requests from bs4 import BeautifulSoup
然后get请求腾讯新闻网url,返回的字符串实质上就是我们手动打开这个网站,然后查看网页源代码所看到的html代码。
wbdata = requests.get(url).text
我们需要的仅仅是某些特定标签里的内容:
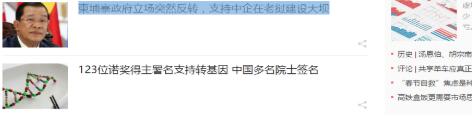
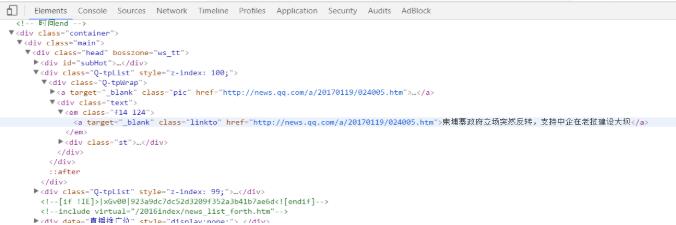
可以看出,每条新闻链接、标题都在<div class="text">标签的<em class="f14 124">标签下
之后我们将刚刚请求得到的html代码进行处理,这时候就需要用到BeautifulSoap库了
soup = BeautifulSoup(wbdata,'lxml')
这一行的意思是对获取的信息进行解析处理,也可以将lxml库换成html.parser库,效果是相同的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行是利用刚刚经过解析获取的soup对象,选择我们需要的标签,返回值是一个列表。列表中存放了我们需要的所有标签内容。也可以使用BeautifulSoup中的find()方法或findall()方法来对标签进行选择。
最后用 for in 对列表进行遍历,分别取出标签中的内容(新闻标题)和标签中href的值(新闻网址),存放在data字典中
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
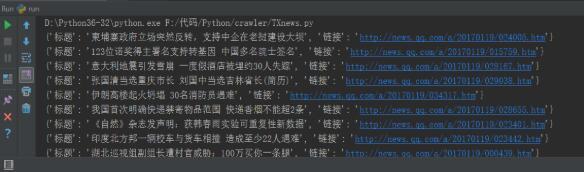
data存放的就是所有的新闻标题和链接了,下图是部分结果
这样一个爬虫就完成了,当然这只是一个最简单的爬虫。深入爬虫的话还有许多模拟浏览器行为、安全问题、效率优化、多线程等等需要考虑,不得不说爬虫是一个很深的坑。
python中爬虫可以通过各种库或者框架来完成,requests只是比较常用的一种而已。其他语言中也会有许多爬虫方面的库,例如php可以使用curl库。爬虫的原理都是一样的,只是用不同语言、不同库来实现的方法不一样。
以上这篇Python 通过requests实现腾讯新闻抓取爬虫的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











