
Saver的用法
1. Saver的背景介绍
我们经常在训练完一个模型之后希望保存训练的结果,这些结果指的是模型的参数,以便下次迭代的训练或者用作测试。Tensorflow针对这一需求提供了Saver类。
Saver类提供了向checkpoints文件保存和从checkpoints文件中恢复变量的相关方法。Checkpoints文件是一个二进制文件,它把变量名映射到对应的tensor值 。
只要提供一个计数器,当计数器触发时,Saver类可以自动的生成checkpoint文件。这让我们可以在训练过程中保存多个中间结果。例如,我们可以保存每一步训练的结果。
为了避免填满整个磁盘,Saver可以自动的管理Checkpoints文件。例如,我们可以指定保存最近的N个Checkpoints文件。
2. Saver的实例
下面以一个例子来讲述如何使用Saver类
import tensorflow as tf
import numpy as np
x = tf.placeholder(tf.float32, shape=[None, 1])
y = 4 * x + 4
w = tf.Variable(tf.random_normal([1], -1, 1))
b = tf.Variable(tf.zeros([1]))
y_predict = w * x + b
loss = tf.reduce_mean(tf.square(y - y_predict))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
isTrain = False
train_steps = 100
checkpoint_steps = 50
checkpoint_dir = ''
saver = tf.train.Saver() # defaults to saving all variables - in this case w and b
x_data = np.reshape(np.random.rand(10).astype(np.float32), (10, 1))
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
if isTrain:
for i in xrange(train_steps):
sess.run(train, feed_dict={x: x_data})
if (i + 1) % checkpoint_steps == 0:
saver.save(sess, checkpoint_dir + 'model.ckpt', global_step=i+1)
else:
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
else:
pass
print(sess.run(w))
print(sess.run(b))
2.1 训练阶段
使用Saver.save()方法保存模型:
训练完成后,当前目录底下会多出5个文件。
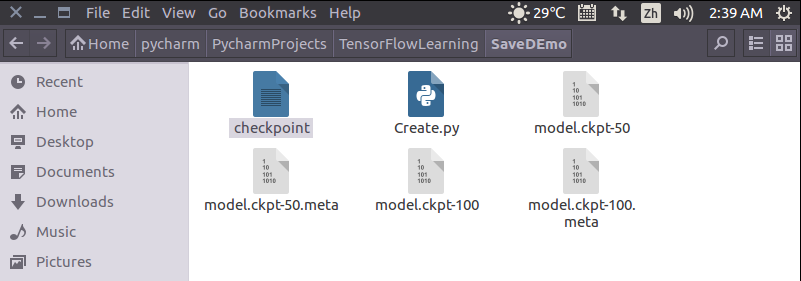
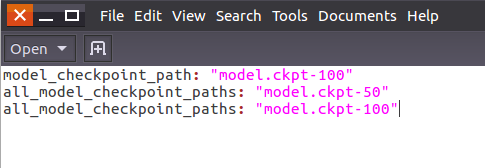
打开名为“checkpoint”的文件,可以看到保存记录,和最新的模型存储位置。
2.1测试阶段
测试阶段使用saver.restore()方法恢复变量:
sess:表示当前会话,之前保存的结果将被加载入这个会话
ckpt.model_checkpoint_path:表示模型存储的位置,不需要提供模型的名字,它会去查看checkpoint文件,看看最新的是谁,叫做什么。
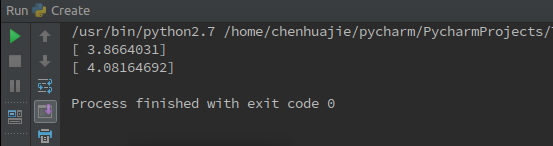
运行结果如下图所示,加载了之前训练的参数w和b的结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。











