
本文介绍了Python3安装Scrapy的方法步骤,分享给大家,具体如下:
一、Scrapy简介
Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中。Scrapy最初就是为了网络爬取而设计的。现在,Scrapy已经推出了曾承诺过的Python3.x版本。
为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Python爬虫程序好比孤军奋战,而使用了Scrapy就好比手底下有了千军万马。Scrapy可以起到事半功倍(甚至好几倍*.*)的效果。所以,学习Scrapy也就显得很有必要了。
二、Scrapy安装
1.直接使用指令pip3 install scrapy,发现有诸多错误。
遇到的错误,如下图所示:



2.解决办法
在http://www.lfd.uci.edu/~gohlke/pythonlibs/有很多用于windows的编译好的Python第三方库,我们下载好对应自己Python版本的库即可。
(1)在cmd中输入指令python,查看python的版本,如下:

从上图可以看出可以看出我的Python版本为Python3.5.2-64bit。
(2)登陆http://www.lfd.uci.edu/~gohlke/pythonlibs/,Ctrl+F搜索Lxml、Twisted、Scrapy,下载对应的版本,例如:lxml-3.7.3-cp35-cp35m-win_adm64.whl,表示lxml的版本为3.7.3,对应的python版本为3.5-64bit。我下载的版本如下图所示:

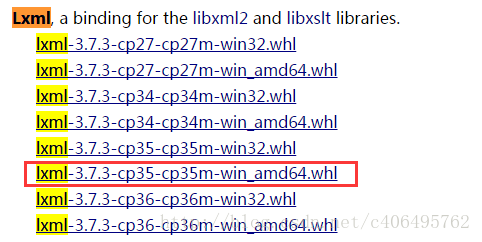
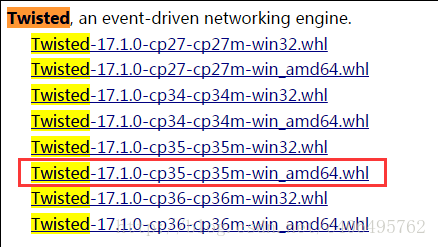
(3)在cmd中输入DOS指令,进入下载好的whl文件夹下,例如我的三个whl文件放在了Scrapy文件夹下:
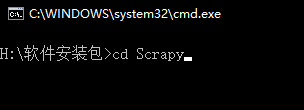
(4)依次执行如下命令:
a.pip3 install wheel

b.pip3 install lxml-3.7.3-cp35-cp35m-win_amd64.whl

c.pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
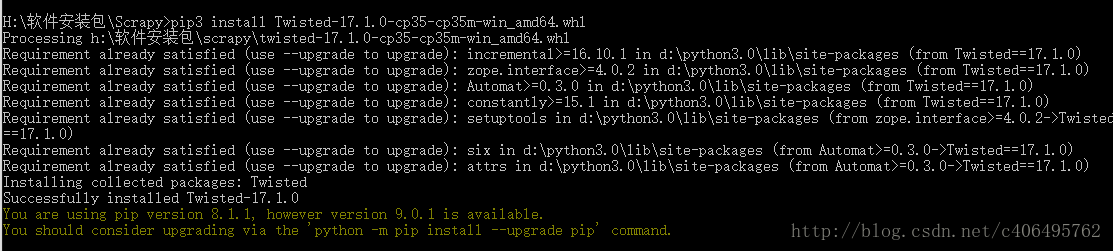
d.pip3 install Scrapy-1.3.2-py2.py3-none-any.whl
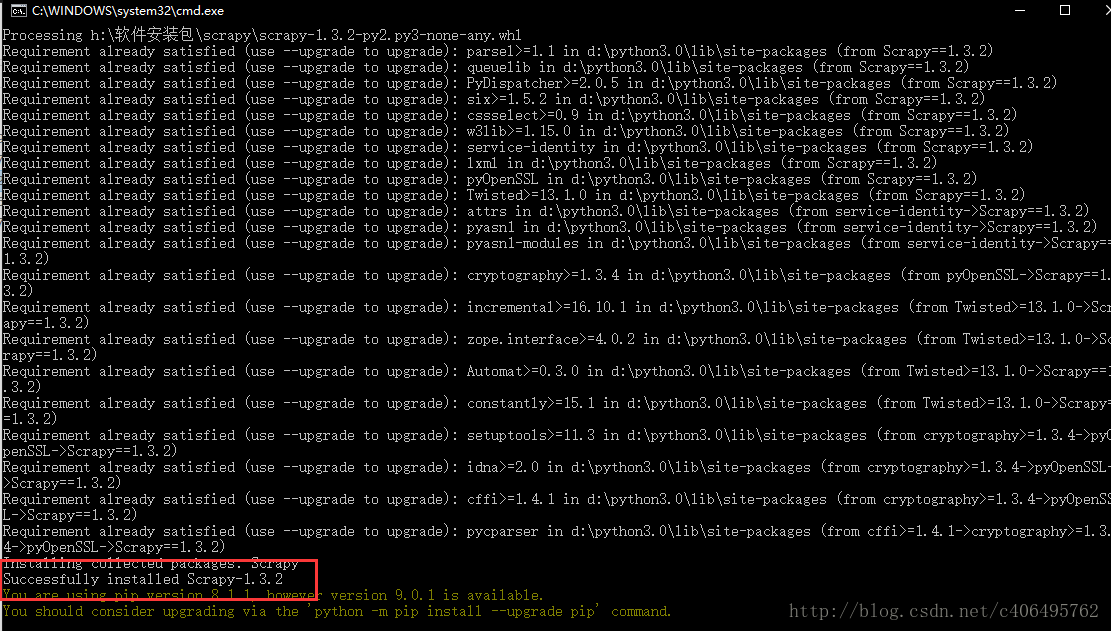
这样Scrapy的安装就完成了,请忽略最后两行让我升级pip的信息。*.*
(5)Srapy已经安装成功,还要下载pywin32,找到对应版本下载,一路下一步安装即可。安装完成后,就可以正常使用Scrapy了。
URL:https://sourceforge.net/projects/pywin32/files/pywin32/Build%20220/
至此,大功告成,我们可以愉快的使用Scrapy了。
常见错误
1、pkg_resources.VersionConflict: (six 1.5.2 (/usr/lib/python3/dist-packages), Requirement.parse('six>=1.6.0'))
six包版本过低,six包是一个提供兼容Python2和Python3的库,升级six包即可。
sudo pip3 install -U six
2、c/_cffi_backend.c:15:17: fatal error: ffi.h: No such file or directory
缺少Libffi这个库。什么是libffi?“FFI” 的全名是 Foreign Function Interface,通常指的是允许以一种语言编写的代码调用另一种语言的代码。而Libffi库只提供了最底层的、与架构相关的、完整的”FFI”。
安装相应的库即可。
Ubuntu、Debian:
sudo apt-get install build-essential libssl-dev libffi-dev python3-dev
CentOS、RedHat:
sudo yum install gcc libffi-devel python-devel openssl-devel
3、ImportError: No module named 'cryptography'
这是缺少加密的相关组件,利用pip安装即可。
sudo pip3 install cryptography
4、ImportError: No module named 'packaging'
缺少packaging这个包,它提供了Python包的核心功能,利用pip安装即可。
sudo pip3 install packaging
5、ImportError: No module named 'appdirs'
缺少appdirs这个包,它用来确定文件目录,利用pip单独安装即可。
sudo pip3 install appdirs
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。










