
前言
由于Django是动态网站,所有每次请求均会去数据进行相应的操作,当程序访问量大时,耗时必然会更加明显,最简单解决方式是使用:缓存,缓存将一个某个views的返回值保存至内存或者Redis中,5分钟内再有人来访问时,则不再去执行view中的操作,而是直接从内存或者Redis中之前缓存的内容拿到,并返回。
首先我们先来了解下浏览器的缓存
浏览器缓存机制
Cache-control策略Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。只不过Cache-Control的选择更多,设置更细致,如果同时设置的话,其优先级高于Expires。

还是上面那个请求,web服务器返回的Cache-Control头的值为max-age=300,即5分钟(和上面的Expires时间一致,这个不是必须的)。

Last-Modified/If-Modified-SinceLast-Modified/If-Modified-Since要配合Cache-Control使用。lLast-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。lIf-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头If-Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified-Since则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包体,节省浏览),告知浏览器继续使用所保存的cache。
在实际中开发应用中,我们会用到缓存,其实在django开发中我们也能用到缓存,现在django给我们很多缓存方式,我看到的有六种之多吧,可能其余的还有,不在追叙,我采用的是利用文件的缓存,说白了就是把缓存的数据放到请求的电脑中,这样也是减少一部分的服务器的压力,那么来看看我的配置。
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache',
}
}
这是我们利用缓存文件的缓存,那么我们配置好了,来看下我们的使用,首先我们可以全局缓存
使用中间件,经过一系列的认证等操作,如果内容在缓存中存在,则使用FetchFromCacheMiddleware获取内容并返回给用户,当返回给用户之前,判断缓存中是否已经存在,如果不存在则UpdateCacheMiddleware会将缓存保存至缓存,从而实现全站缓存
设置如下:
MIDDLEWARE = [ 'django.middleware.cache.UpdateCacheMiddleware',#放到第一个中间件位置 # 其他中间件... 'django.middleware.cache.FetchFromCacheMiddleware',#放到最后一个 ] CACHE_MIDDLEWARE_ALIAS = "" CACHE_MIDDLEWARE_SECONDS = "" CACHE_MIDDLEWARE_KEY_PREFIX = ""
还有就是我们对单独的视图进行缓存:
方法一:直接应用加入装饰器
from django.views.decorators.cache import cache_page@cache_page(60*15)
def ceshi(request):
posts=Article.objects.filter(tag__name=u'测试')
post_list = fenye(request, posts=posts)
return render(request, 'index.html', {'post_list': post_list,})
其实我还用到另外的方式,那就是在url处增加,因为我的是面向对象的编程方式所以我利用下面的。
url(r'^$', cache_page(60*2)(HomeView.as_view()), name='home'),
这样我们配置好,启动我们的项目,然后我们可以去看看我们的缓存是否生效,首先我们看下
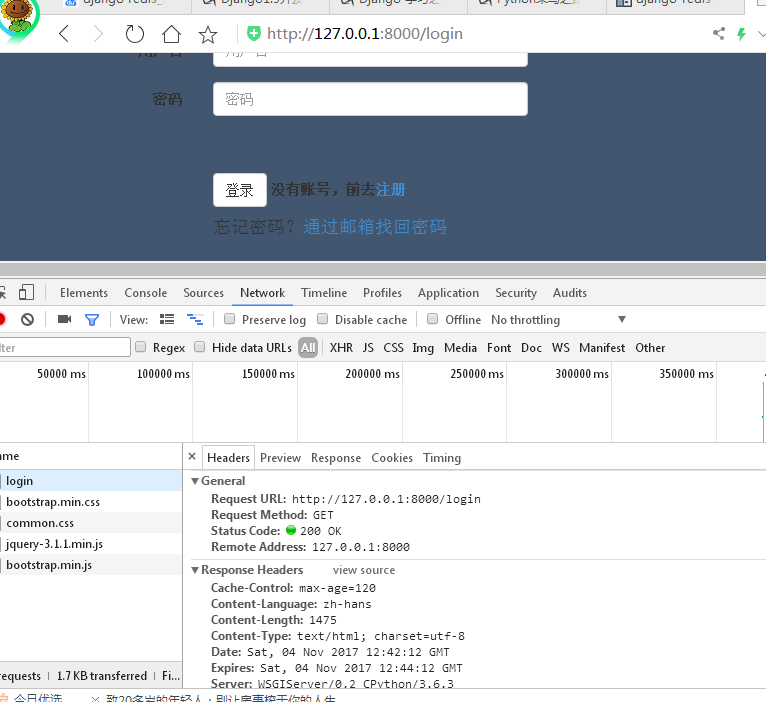
可以看到,我在登陆界面做了两分钟的缓存,那么我们来看看我们的文件是否生效呢。
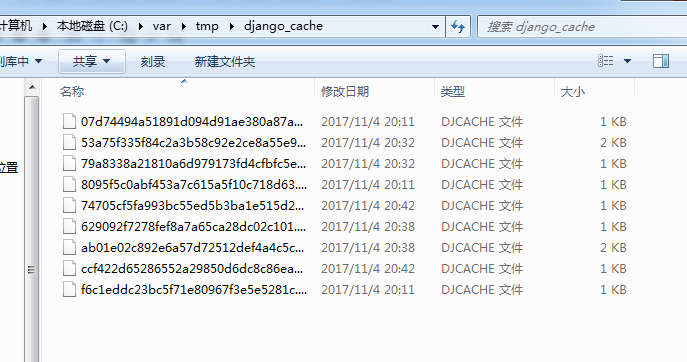
这样可以证明我们现在的缓存是成功的,其实我们还可以利用redis等来缓存。
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。











