
场景
产品中有一张图片表pics,数据量将近100万条,有一条相关的查询语句,由于执行频次较高,想针对此语句进行优化
表结构很简单,主要字段:
一个用户会有多条图片记录,现在有一个根据user_id建立的索引:uid,查询语句也很简单:取得某用户的图片集合:
执行查询语句(为了查看真实执行时间,强制不使用缓存,为了防止在测试时因为读取了缓存造成对时间上的差别)
使用explain进行分析:

使用了user_id的索引,并且是const常数查找,表示性能已经很好了
优化后
因为这个语句太简单,sql本身没有什么优化空间,就考虑了索引
修改索引结构,建立一个(user_id,picname,smallimg)的联合索引:uid_pic
重新执行10次,平均耗时降到了30ms左右
使用explain进行分析

看到使用的索引变成了刚刚建立的联合索引,并且Extra部分显示使用了'Using Index'
总结
‘Using Index'的意思是“覆盖索引”,它是使上面sql性能提升的关键
一个包含查询所需字段的索引称为“覆盖索引”
MySQL只需要通过索引就可以返回查询所需要的数据,而不必在查到索引之后进行回表操作,减少IO,提高了效率
例如上面的sql,查询条件是user_id,可以使用联合索引,要查询的字段是picname smallimg,这两个字段也在联合索引中,这就实现了“覆盖索引”,可以根据这个联合索引一次性完成查询工作,所以提升了性能。
扩展研究
一、Mysql缓存,SQL_NO_CACHE和SQL_CACHE 的区别
上边在进行测试的时候,为了防止读取缓存造成对实验结果的影响使用到了SQL_NO_CACHE这个功能,对于SQL_NO_CACHE的介绍官网如下:
当我们想用SQL_NO_CACHE来禁止结果缓存时发现结果和我们的预期不一样,查询执行的结果仍然是缓存后的结果。其实,SQL_NO_CACHE的真正作用是禁止缓存查询结果,但并不意味着cache不作为结果返回给query。
在说白点就是,不是本次查询不使用缓存,而是本次查询结果不做为下次查询的缓存。
还有就是,mysql本身是有对sql语句缓存的机制的,合理设置我们的mysql缓存可以降低数据库的io资源,因此,这里我们有必要再看一下如何控制这个比较安逸的功能。
看图如下:
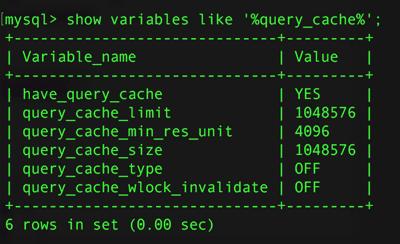
其中各项的含义为:
1、have_query_cache
是否支持查询缓存区 “YES”表是支持查询缓存区
2、query_cache_limit
可缓存的Select查询结果的最大值 1048576 byte /1024 = 1024kB 即最大可缓存的select查询结果必须小于 1024KB
3、query_cache_min_res_unit
每次给query cache结果分配内存的大小 默认是 4096 byte 也即 4kB
4、query_cache_size
如果你希望禁用查询缓存,设置 query_cache_size=0。禁用了查询缓存,将没有明显的开销
5、query_cache_type
查询缓存的方式(默认是 ON)
1、完整查询的过程如下
当查询进行的时候,Mysql把查询结果保存在qurey cache中,但是有时候要保存的结果比较大,超过了query_cache_min_res_unit的值 ,这时候mysql将一边检索结果,一边进行慢慢保存结果,所以,有时候并不是把所有结果全部得到后再进行一次性保存,而是每次分配一块query_cache_min_res_unit 大小的内存空间保存结果集,使用完后,接着再分配一个这样的块,如果还不不够,接着再分配一个块,依此类推,也就是说,有可能在一次查询中,mysql要进行多次内存分配的操作,而我们应该知道,频繁操作内存都是要耗费时间的。
2、内存碎片的产生
当一块分配的内存没有完全使用时,MySQL会把这块内存Trim掉,把没有使用的那部分归还以重复利用。比如,第一次分配4KB,只用了3KB,剩1KB,第二次连续操作,分配4KB,用了2KB,剩2KB,这两次连续操作共剩下的1KB+2KB=3KB,不足以做个一个内存单元分配,这时候,内存碎片便产生了。
3.内存块的概念
先看下这个:
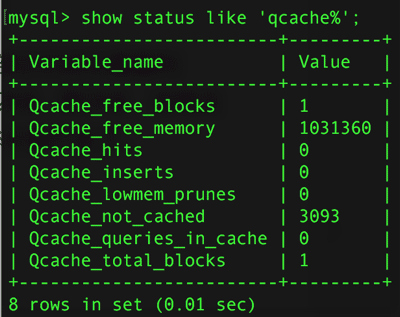
Qcache_total_blocks 表示所有的块
Qcache_free_blocks 表示未使用的块
这个值比较大,那意味着,内存碎片比较多,用flush query cache清理后,为被使用的块其值应该为1或0 ,因为这时候所有的内存都做为一个连续的快在一起了.
Qcache_free_memory 表示查询缓存区现在还有多少的可用内存
Qcache_hits 表示查询缓存区的命中个数,也就是直接从查询缓存区作出响应处理的查询个数
Qcache_inserts 表示查询缓存区此前总过缓存过多少条查询命令的结果
Qcache_lowmem_prunes 表示查询缓存区已满而从其中溢出和删除的查询结果的个数
Qcache_not_cached 表示没有进入查询缓存区的查询命令个数
Qcache_queries_in_cache 查询缓存区当前缓存着多少条查询命令的结果
优化提示:
如果Qcache_lowmem_prunes 值比较大,表示查询缓存区大小设置太小,需要增大。
如果Qcache_free_blocks 较多,表示内存碎片较多,需要清理,flush query cache
关于query_cache_min_res_unit大小的调优,书中给出了一个计算公式,可以供调优设置参考:
二、覆盖索引(偷懒整理一下,来自百度百科)
理解方式一:就是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。
理解方式二:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引。
理解方式三:是非聚集复合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段,也即,索引包含了查询正在查找的数据)。
作用:
如果你想要通过索引覆盖select多列,那么需要给需要的列建立一个多列索引,当然如果带查询条件,where条件要求满足最左前缀原则。
Innodb的辅助索引叶子节点包含的是主键列,所以主键一定是被索引覆盖的。
(1)例如,在sakila的inventory表中,有一个组合索引(store_id,film_id),对于只需要访问这两列的查 询,MySQL就可以使用索引,如下:
此时,建立复合索引”created, id”(只要建立created索引就可以吧,Innodb是会在辅助索引里面存储主键值的),就可以在子查询里利用上Covering Index,快速定位id,查询效率嗷嗷的
注:本文是参考《Mysql性能优化案例 - 覆盖索引》 的一篇文章借题发挥,参考了原文的知识点,自己做了一点的发挥和研究,原文被多次转载,不知作者何许人也,也不知出处在哪个,如需原文请自行搜索。











