
今天的文章给大家谈谈在SQL Server上关于indexing的一个特定的性能问题。
问题
看看下面的简单的query语句,可能你已经在你看到过几百次了
-- Results in an Index Scan SELECT * FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = 2005 AND MONTH(OrderDate) = 7 GO
上门的代码查询一个销售信息,需要一个特定的月份和年份的,这不是很复杂。但是不幸的的事,这个qeury的效率不行,即使OrderDate这一列已经做了Non-Clustered Index。可以看看下面的qeury执行图,你能看到Query Optimizer已经选择了定义在列OrderDate下的Non-Clustered Index,但是SQL Server却做了Index的一个完整扫描,而不是期待中的Seek operation。
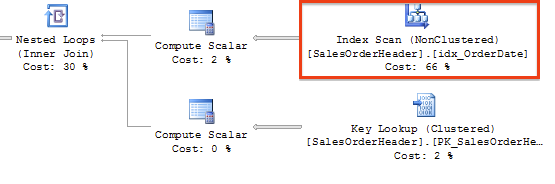
这实际上不是SQL Server的限制,而是relational database都是这样的。只要你对一个做了index的列(Search Argument)加了函数操作,数据库引擎就必须再次扫描这个index,而不是去直接执行seek operation
解决方案
为了解决上门的问题,必须要避免在列上门直接应该函数,比如上面的问题可以用下面的代码来代替
-- Results in an Index Seek SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate >= '20050701' AND OrderDate < '20050801' GO
我们重写的这个query语句,能达到同样的效果,不用函数MONTH了。从此query的执行图来看,SQL Server执行了seek operation,在查询的范围内进行的scan。所以,如果你要在where查询中用到函数,用到表达式的右侧,来避免性能问题。比如下面的例子。
-- Results in an Index Scan SELECT * FROM Sales.SalesOrderHeader WHERE CAST(CreditCardID AS CHAR(4)) = '1347' GO
这个query会使SQL Server扫描了整个Non-Clustered Index。所以当表变得更大的时候,这个扩展性等各方面就很差了。如果把函数放在表达式的右侧,SQL Server就能执行seek operation了
-- Results in an Index Seek
SELECT * FROM Sales.SalesOrderHeader
WHERE CreditCardID = CAST('1347' AS INT)
GO
通过今天的blog,我想你们已经认识到了不要在做过indexed的列上直接应用函数,不然SQL Server会扫描你整个index,而不是做seek operation。当你的表变得越来越大的时,你会崩溃的。
译后记
这也是我在看微软SQL Server认证考试Exam70-461的TrainingKit的时候,它书里面反复强调的。简单来讲就是保证不要直接用函数作用在做过index的列上,要用函数的话,变通到表达式的右侧来。至于为什么会影响性能。因为我对index还不熟悉,我理解的不是很清晰。
我大概猜想如下,先记下,欢迎讨论。
对某一个列做index,是不是类似对这一列的数据做一个hash映射,当在查找这一列的数据的时候,直接可以做O(1)的操作(是不是就是它讲的seek operation)。如果对这一列使用了函数,SQL Server的机制就是不会重新做一个作用了函数后的列的hash,它就简单的一个一个的比较了。是O(N)的操作了。











