聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。
SQL Server中的索引使用标准的B-树来存储他们的信息,如下图所示,B-树通过查找索引中的一个关键之来提供对于数据的快速访问,B-树以相似的键记录聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-树的一个核心作用就是保持树的平衡。同伙向下遍历这棵树以找到一个数值并定位记录。因为树是平衡的,所以寻找任何记录都只需要等量的资源,而且获取的速度总是一致的—因为从根索引叶索引都具有相同的深度。
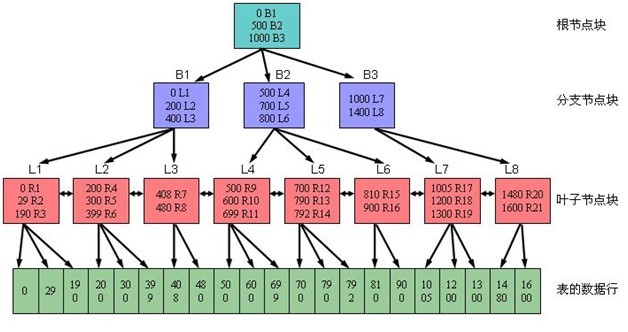
索引的中间层次是根据表的行数一级索引行的大小而变化的,如果使用一个较长的键(KEY)来创建索引,一个分页上就只容纳较少的条目,因而索引就需要更多分页(或者说更多层),页越多那么查找就需要话费相对较长的时间来找到所需要的信息,索引就可能不太有用了。
聚集索引聚集索引的叶级别不仅包含了索引键,还包含了数据页。另一种说法数据本身也是聚集索引的一部分,聚集索引基于键值保持表中的数据有序,表中的数据页是通过一个被称作页链(page chain)的双向链接表来维护的,由于实际的数据页的页链只能按一种方式排序,因此一张表只能拥有一个聚集索引。
这里可能有一个误区,有很多介绍SQL Server索引的文档会告诉读者:聚集索引按照排序顺序(sorted order)物理地存储数据。如果以为物理存储就是磁盘本身的话就会产生误解。试想如果聚集索引需要按照特定顺序在实际的磁盘上维护数据的话,那么任何修改操作都将会产生相当高昂的代价。当一个页变满了需要一分为二的时候,所有后续页面上的数据都必须向后移动。聚集索引中的排序顺序(sorted order)仅仅表示数据页链在逻辑上是有序的。
大多数表都应该需要一个聚集索引。优化器非常倾向于采用聚集索引,因为聚集索引能够直接在叶级别找到数据。由于定义了数据的逻辑顺序,聚集索引能够特别快的访问针对范围值的查询,查询优化器能够发现只有某一段范围的数据页需要扫描。
非聚集索引对于非聚集索引,叶级别不包含全部的数据。除了键值之外,每个叶级别(树的最底层)中的索引行包含了一个书签(bookmark),告诉SQL Server可以在那里找到与索引键相应的数据行。一个书签可能有两种形式。如果表上存在聚集索引,书签就是相应的数据行的聚集索引键。如果彪是堆(heap)结构,书签就是一个行表示(row identifier,RID),以“文件号:页号:槽号”的格式来定位实际的行。
主键(PRIMARY KEY)与聚集索引(CLUSTER INDEX)严格来说,主键与聚集索引没有任何关系,如果要说有话,那就是表中没有聚集索引的时候,创建的主键默认就是聚集索引(除非有特别设置为NOCLUSTER)。
在主键与聚集索引的处理方面,注意以下事项:
1、主键不与聚集索引分离
2、聚集索引键列尽量避免使用int之外的数据类型
3、尽量避免使用复合主键
创建索引时的注意事项1、始终包含聚集索引当表中不包含聚集索引时,表中的数据是无序的,这会降低数据检索效率。即使通过索引缩小了数据检索的范围,但由于数据本身是无序的,当从表中提取实际数据时,会产生频繁的定位问题,这也使得SQL Server基本上不会使用无聚集索引表中的索引来检索数据。
2、保证聚集索引唯一由于聚集索引是非聚集索引的行定位器,如果它不唯一,则会使行定位器中包含辅助数据,同时也导致从表中提取数据时,需要借助行定位器中的辅助数据来定位,这会降低处理效率。
3、保证聚集索引最小每个聚集键值都是所有非聚集索引的叶结点记录,它越小,意味着每个非聚集索引的索引叶包含的有效数据越多,这对于提升索引效率很有好处。
4、覆盖索引覆盖索引是指索引中的列包含了数据处理中涉及的所有列,覆盖索引相当原始表的一个子集,由于这个子集中包含了数据处理涉及的所有列,因此操作这个子集就可以满足数据处理需要。一般而言,如果大多数处理都只涉及某个大表的某些列,可以考虑为这些列建立覆盖索引。
覆盖索引的建立方法是将要包含的列中的关键列做为索引键列,将其他列做为索引的包含列(使用索引创建语句中的INCLUDE子句)。
5、适量的索引当数据发生变化时,SQL Server会同步维护相关索引中的数据,过多的索引会加影响数据变更的处理效率。因此,只应该在经常使用的列上建立索引。
适量的索引还体现在对索引列的组合方式的控制上。例如,如果有两个列col1和col2,这两个列的组合会产生三种使用情况:单独使用col1、单独使用col2及同时使用col1和col2。如果有为每种情况都建立索引,则需要建立三个索引。但也可以只建立一个复合索引(col1, col2),这样能够依次满足col1+col2、col1、col2这三种方式的查询,其中,col2利用这个查询会比较勉强(还要配合单独的统计),可以视实际情况确定是否需要为col2建立单独的索引。
特别注意:
不要建立重复索引,目前最常见的重复索引是单独为某个列建立主键和聚集索引
与直接从表中提取数据相比,根据索引检索数据,多了一个索引检索的过程,这个过程要求能够尽量缩小数据检索范围,并且使用最少的时间,这样才能真正保证能够通过索引提高数据检索效率。
实现上述目的,对于索引键列的选择,应该遵循如下原则:
选择性原则选择性是满足条件的记录占总记录数的百分比,这个比率应该尽可能低,这样才能保证通过索引扫描后,只需要从基础表提取很少的数据。
如果这个比率偏高,则不应该考虑在此列上建立索引。
数据密度原则数据密度是指列值唯一的记录占总记录数的百分比,这个比率越高,则说明此列越适合建立索引。
在考虑数据密度的时候,还要注意数据分布的问题,只有经常检索的密度高时,才适合建立索引。例如,如果一张表有10万记录,虽然某个列不重复的记录有9万条,但如果经常检索的2万条记录,其不重复的列值才几十条的话,这个列是不太适合建立索引的。另一种情况是,整体数据密度不大,但经常检索的数据的密度大,例如订单的状态,一般来说,订单的状态就几种,但已经Close的订单往往占整个数据的绝大部分,但数据处理的时候,基本上都是检索未Close的订单,这种情况下,为订单的状态列建立索引还是比较有效的(SQL Server 2008中,可以为这种列建立具有更佳效果的筛选索引)。
6、索引键列大小一般不宜为超过100Byte的列建立索引。
7、复合索引键列顺序在索引中,索引的顺序主要由索引中的每一个键列确定,因此,对于复合索引,索引中的列顺序是很重要的,应该优先把数据密度大,选择性列,存储空间小的列放在索引键列的前面。
链接:http://topic.csdn.net/u/20120721/10/b057fc3b-4304-44ee-b7b5-16160f30bacc.html?seed=656570155&r=79190463#r_79190463
作者 Beirut(小爱)












