
puppeteer 是一个Chrome官方出品的headless Chrome node库。它提供了一系列的API, 可以在无UI的情况下调用Chrome的功能, 适用于爬虫、自动化处理等各种场景
根据官网上描述,puppeteer 具有以下作用:
以下就来阐述 puppeteer 的这几个作用
1.初始化项目
注: 这里我们会使用到 es6/7 的新特性,所以用 typescript 来编译代码
npm install puppeteer typescript @types/puppeteer
tsconfig.json 配置如下:
{
"compileOnSave": true,
"compilerOptions": {
"target": "es5",
"lib": [
"es6", "dom"
],
"types": [
"node"
],
"outDir": "./dist/",
"sourceMap": true,
"module": "commonjs",
"watch": true,
"moduleResolution": "node",
"isolatedModules": false,
"experimentalDecorators": true,
"declaration": true,
"suppressImplicitAnyIndexErrors": true
},
"include": [
"./examples/**/*",
]
}
puppeteer 模块提供一个方法启动一个 Chromium 实例。
import * as puppeteer from 'puppeteer'
(async () => {
await puppeteer.launch()
})()
上述代码通过 puppeteer 的 launch 方法生成一个 browser 实例,launch 方法可以接收一些配置项。较为常用的有:
2.生成页面截图
这里我们以 https://example.com/ 为例
(async () => {
const browser = await puppeteer.launch(); //生成browser实例
const page = await browser.newPage(); //解析一个新的页面。页面是在默认浏览器上下文创建的
await page.goto("https://example.com/"); //跳转到 https://example.com/
await page.screenshot({ //生成图片
path: 'example.png'
})
})()
在这里需要注意的是,截图默认截取的是打开网页可视区的内容,如果要获取完整的可滚动页面的屏幕截图,需要添加 fullPage: true
执行 node dist/screenshot.js ,即可在根目录下生成 example.png
puppeteer 默认将页面大小设置为 800*600,可以通过 page.setViewport() 来改变页面大小。
不仅如此,puppeteer 还可以模拟手机
import * as puppeteer from "puppeteer";
import * as devices from "puppeteer/DeviceDescriptors";
const iPhone = devices["iPhone 6"];
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.emulate(iPhone);
await page.goto("https://baidu.com/");
await browser.close();
})();
3.生成 pdf
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://example.com/");
await page.pdf({
displayHeaderFooter: true,
path: 'example.pdf',
format: 'A4',
headerTemplate: '<b style="font-size: 30px">Hello world<b/>',
footerTemplate: '<b style="font-size: 30px">Some text</b>',
margin: {
top: "100px",
bottom: "200px",
right: "30px",
left: "30px",
}
});
await browser.close();
})()
执行 node dist/pdf.js 即可。
4.自动化表单提交, 输入
在这里我们模拟一下京东的登录, 为了能更好的看到整个过程, 我们使用 headless: false 来关闭 headless 模式,看一下整个的登录流程
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto("https://github.com/login");
await page.waitFor(1000) //延迟1秒输入
await page.type("#login_field", "1137060420@qq.com"); //立即输入
await page.type("#password", "bian1992518", {
delay: 100
}) //模拟用户输入
await page.click("input[type=submit]"); //点击登录按钮
})()
5.站点时间线追踪
可以很方便的使用 tracking.start 和 tracking.stop 创建一个可以在 chrome devtools 打开的跟踪文件
(async () => {
const broswer = await puppeteer.launch();
const page = await broswer.newPage();
await page.tracing.start({
path: "trace.json"
});
await page.goto("https://example.com/");
await page.tracing.stop();
broswer.close();
})();
执行 node dist/trace.js 会生成一个 trace.json 文件, 然后我们打开 chrome devtools -> Performance, 然后把该文件直接拖进去即可。该功能便于我们对网站进行性能分析, 进而优化性能
6.爬虫和 SSR
现在大多数开发用 react、vue、angular 来构建 SPA 网站, SPA 固有很多的优点, 比方开发速度快、模块化、组件化、性能优等。但其缺点还是很明显的, 首先就是首屏渲染问题, 其次不利于 SEO, 对爬虫不友好。
以 https://preview.pro.ant.design/#/dashboard/analysis 为例, 我们点击右键, 查看源代码, 发现其 body 里面只有 <div id="root"></div> ,假如想把门店销售额排名情况给爬下来,存到数据库进行数据分析(如下图)
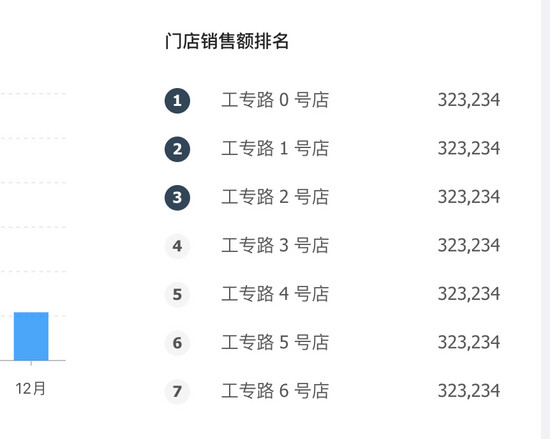
此时我们以传统爬虫的方式去爬的话是拿不到网页内容的。
如 python
# -*- coding : UTF-8 -*-
from bs4 import BeautifulSoup
import urllib2
def spider():
html = urllib2.urlopen('https://preview.pro.ant.design/#')
html = html.read()
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify())
if __name__ == '__main__':
spider()
执行 python py/index.py , 得到的结果如下图:
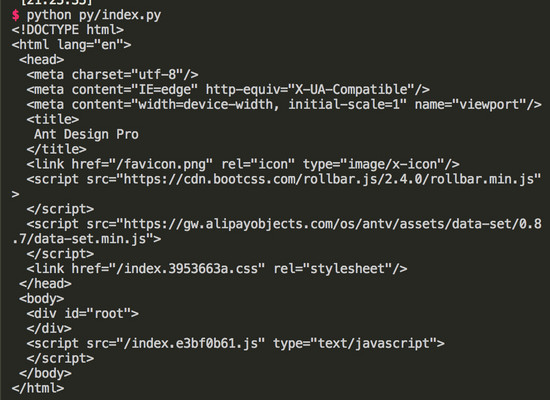
body 里面并没有页面相关的 dom,因此我们想通过 python 去爬取 SPA 页面的内容是不可行的。
nodejs
import axios from "axios";
(async () => {
const res = await axios.get("https://preview.pro.ant.design/#");
console.log(res.data);
})();
执行 node dist/node-spider.js , 得到和上面例子一样的结果。
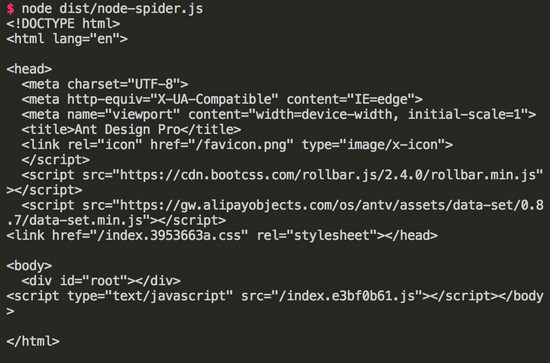
puppeteer
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://preview.pro.ant.design/#");
console.log(await page.content());
})();
执行 node dist/spider.js , 得到如下:
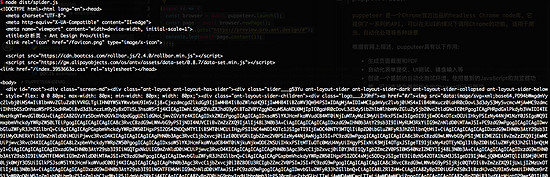
此时我们可以惊奇的发现可以抓到页面所有的 dom 节点了。此时我们可以把它保存下来做 SSR,也可以爬取我们想要的内容了。
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://preview.pro.ant.design/#");
const RANK = ".rankingList___11Ilg li";
await page.waitForSelector(RANK);
const res = await page.evaluate(() => {
const getText = (v, selector) => {
return v.querySelector(selector) && v.querySelector(selector).innerText;
};
const salesRank = Array.from(
document.querySelectorAll(".rankingList___11Ilg li")
);
const data = [];
salesRank.map(v => {
const obj = {
rank: getText(v, "span:nth-child(1)"),
address: getText(v, "span:nth-child(2)"),
sales: getText(v, "span:nth-child(3)")
};
data.push(obj);
});
return {
data
};
});
console.log(res);
await browser.close();
})();
执行 node dist/spider.js , 得到如下:
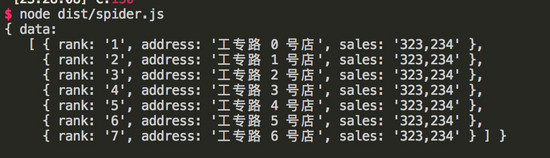
此时,我们已经利用 puppeteer 把我们所需要的数据给爬下来了。
到此,我们就把 puppeteer 基本的功能点给实现了一遍,本文示例代码可在 github 上获取。
参考
https://github.com/GoogleChrome/puppeteer
https://pptr.dev/#?product=Puppeteer&version=v1.6.0
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。










