
jdk1.7.0_79
HashMap可以说是每个Java程序员用的最多的数据结构之一了,无处不见它的身影。关于HashMap,通常也能说出它不是线程安全的。这篇文章要提到的是在多线程并发环境下的HashMap——ConcurrentHashMap,显然它必然是线程安全的,同样我们不可避免的要讨论散列表,以及它是如何实现线程安全的,它的效率又是怎样的,因为对于映射容器还有一个Hashtable也是线程安全的但它似乎只出现在笔试、面试题里,在现实编码中它已经基本被遗弃。
关于HashMap的线程不安全,在多线程并发环境下它所带来的影响绝不仅仅是出现脏数据等数据不一致的情况,严重的是它有可能带来程序死循环,这可能有点不可思议,但确实在不久前的项目里同事有遇到了CPU100%满负荷运行,分析结果是在多线程环境下HashMap导致程序死循环。对于Hashtable,查看其源码可知,Hashtable保证线程安全的方式就是利用synchronized关键字,这样会导致效率低下,但对于ConcurrentHashMap则采用了不同的线程安全保证方式——分段锁。它不像Hashtable那样将整个table锁住而是将数组元素分段加锁,如果线程1访问的元素在分段segment1,而线程2访问的元素在分段segment2,则它们互不影响可以同时进行操作。如果合理的进行分段就是其关键问题。
ConcurrentHashMap和HashMap的结果基本一致,同样也是Entry作为存放数据的对象,另外一个就是上面提到的分段锁——Segment。它继承自ReentrantLock(关于ReentrantLock,可参考《5.Lock接口及其实现ReentrantLock》),故它具有ReentrantLock一切特性——可重入,独占等。
ConcurrentHashMap的结构图如下所示:
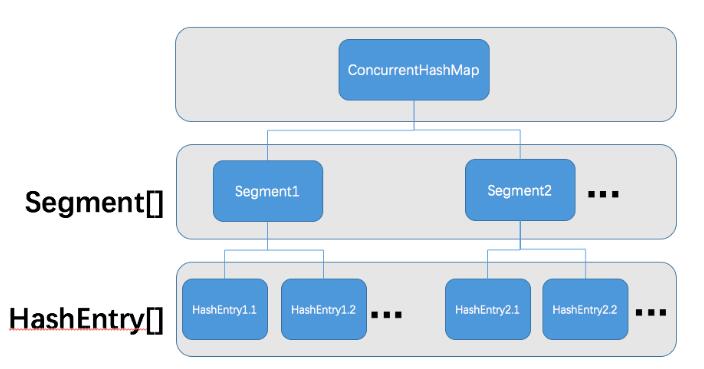
可以看到相比较于HashMap,ConcurrentHashMap在Entry数组之上是Segment,这个就是我们上面提到的分段锁,合理的确定分段数就能更好的提高并发效率,我们来看ConcurrentHashMap是如何确定分段数的。
ConcurrentHashMap的初始化时通过其构造函数public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)完成的,若在不指定各参数的情况下,初始容量initialCapacity=DAFAULT_INITIAL_CAPACITY=16,负载因子loadFactor=DEFAULT_LOAD_FACTOR=0.75f,并发等级concurrencyLevel=DEFAULT_CONCURRENCY_LEVEL=16,前两者和HashMap相同。至于负载因子表示一个散列表的空间的使用程度,initialCapacity(总容量) * loadFactor(负载因子) = 数据量,有此公式可知,若负载因子越大,则散列表的装填程度越高,也就是能容纳更多的元素,但这样元素就多,链表就大,此时索引效率就会降低。若负载因子越小,则相反,索引效率就会高,换来的代价就是浪费的空间越多。并发等级它表示估计最多有多少个线程来共同修改这个Map,稍后可以看到它和segment数组相关,segment数组的长度就是通过concurrencyLevel计算得出。
//以默认参数为例initalCapacity=16,loadFactor=0.75,concurrencyLevel=16
public ConcurrentHashMap(int initalCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;//segment数组长度
while (ssize < concurrencyLevel) {
++sshift;
ssize <= 1;
}//经过ssize左移4位后,ssize=16,ssift=4
/*segmentShift用于参与散列运算的位数,segmentMask是散列运算的掩码,这里有关的散列函数运算和HashMap有类似之处*/
this.segmentShift = 32 – ssift;//段偏移量segmentShift=28
this.segmentMask = ssize – 1;//段掩码segmentMask=15(1111)
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;//c = 1
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;//MIN_SEGMENT_TABLE_CAPACITY=2
while (cap < c)//cap = 2, c = 1,false
cap <<= 1;//cap是segment里HashEntry数组的长度,最小为2
/*创建segments数组和segment[0]*/
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[]) new HashEntry[cap]);//参数意为:负载因子=1,数据容量=(int)(2 * 0.75)=1,总容量=2,故每个Segment的HashEntry总容量为2,实际数据容量为1
Segment<K,V> ss = (Segment<K,V>[])new Segment[ssize];//segments数组大小为16
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
以上就是整个初始化过程,主要是初始化segments的长度大小以及通过负载因子确定每个Segment的容量大小。确定好Segment过后,接下来的重点就是如何准确定位Segment。定位Segment的方法就是通过散列函数来定位,先通过hash方法对元素进行二次散列,这个算法较为复杂,其目的只有一个——减少散列冲突,使元素能均匀分布在不同的Segment上,提高容器的存取效率。
我们通过最直观最常用的put方法来观察ConcurrentHashMap是如何通过key值计算hash值在定位到Segment的:
//ConcurrentHashMap#put
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);//根据散列函数,计算出key值的散列值
int j = (hash >>> segmentShift) & segmentMask;//这个操作就是定位Segment的数组下标,jdk1.7之前是segmentFor返回Segment,1.7之后直接就取消了这个方法,直接计算数组下标,然后通过偏移量底层操作获取Segment
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);//通过便宜量定位不到就调用ensureSegment方法定位Segment
return s.put(key, hash, value, false);
}
Segment.put方法就是将键、值构造为Entry节点加入到对应的Segment段里,如果段中已经有元素(即表示两个key键值的hash值重复)则将最新加入的放到链表的头),整个过程必然是加锁安全的。
不妨继续深入Segment.put方法:
//Segment#put
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);//非阻塞获取锁,获取成功node=null,失败
V oldValue;
try {
HashEntry<K,V>[] tab = table;//Segment对应的HashEntry数组长度
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);//获取HashEntry数组的第一个值
for (HashEntry<K,V> e = first;;) {
if (e != null) {//HashEntry数组已经存在值
K k;
if ((k = e.key) == key || (e.hash == hash && key.equals(k))) {//key值和hash值都相等,则直接替换旧值
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;//不是同一个值则继续遍历,直到找到相等的key值或者为null的HashEntry数组元素
}
else {//HashEntry数组中的某个位置元素为null
if (node != null)
node.setNext(first);//将新加入节点(key)的next引用指向HashEntry数组第一个元素
else//已经获取到了Segment锁
node = new HashEntry<K,V>(hash, key, value, first)
int c = count + 1;
if (c > threshold && tab.lenth < MAXIUM_CAPACITY)//插入前先判断是否扩容,ConcurrentHashMap扩容与HashMap不同,ConcurrentHashMap只扩Segment的容量,HashMap则是整个扩容
rehash(node);
else
setEntryAt(tab, index, node);//设置为头节点
++modCount;//总容量
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
上面大致就是ConcurrentHashMap加入一个元素的过程,需要明白的就是ConcurrentHashMap分段锁的概念。在JDK1.6中定位Segment较为简单,直接计算出Segment数组下标后就返回具体的Segment,而JDK1.7则通过偏移量来计算,算出为空时,还有一次检查获取Segment,猜测是1.7使用底层native是为了提高效率,JDK1.8的ConcurrentHashMap又有不同,暂未深入研究,它的数据结果似乎变成了红黑树。
有关ConcurrentHashMap的get方法不再分析,过程总结为一句话:根据key值计算出hash值,根据hash值计算出对应的Segment,再在Segment下的HashEntry链表遍历查找。
以上这篇基于Java并发容器ConcurrentHashMap#put方法解析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。











