分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。
分治法解题的一般步骤:
(1)分解,将要解决的问题划分成若干规模较小的同类问题;
(2)求解,当子问题划分得足够小时,用较简单的方法解决;
(3)合并,按原问题的要求,将子问题的解逐层合并构成原问题的解。
一言以蔽之:分治法的设计思想是,将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
在认识分治之前很有必要先了解一下递归,当然,递归也是最基本的编程问题,一般接触过编程的人都会对递归有一些认识.为什么要先了解递归呢?你看,根据上面所说的,我们就要将一个问题分成若干个小问题,然后一一求解并且最后合并,这就是一个递归的问题,递归的去分解自身,递归的去解决每一个小问题,然后合并…
关于递归,这里举一个最简单的例子,求N!;
我们只需要定义函数
{
if(n==1)
return 1;
else
return n*calculate(n-1); //调用自身…
}
好了,有了递归的铺垫,我们下来来看一看一个分治算法的问题,归并排序问题…
基本思想:
将待排序元素分成大小大致相同的2个子集合(递归直到最小的排序单元),分别对2个子集合进行排序,最终将排好序的子集合合并成为所要求的排好序的集合。
下面我们用一张图来展示整个流程,最下面的(姑且叫他第一层)是原始数组分成了8个最小排序问题,各自只有一个元素,故不需要排序,大家可以看到,我们通过分而治之的思想把对最初数组的排序分为了若干个只有一个元素的小数组的排序,然后第二层,我们进行了合并,将每两个最小排序结果合并为有两个元素的数组,然后逐层往上进行合并,就有了最后的结果…
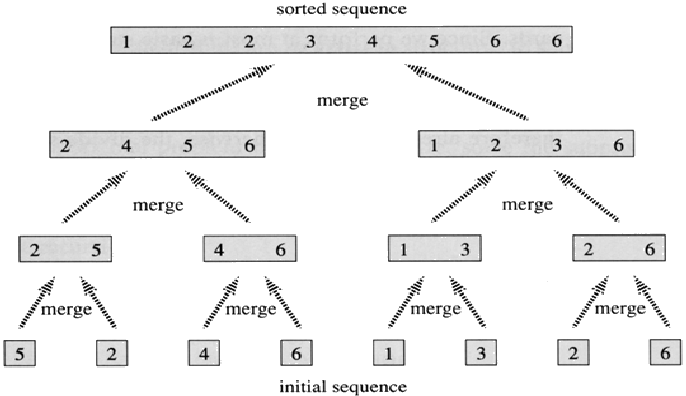
下面我们来看一下这个算法的具体实现,下面的MERGE-SORT (A, p, r)表示对数组A[p->r]的排序过程.其中p->r代表从p到r.
MERGE-SORT (A, p, r)
1. IF p < r // 进行A[p->r]的排序过程自然需要p<r的前提条件
2. THEN q = [(p + r)/2] // 将当前的排序问题一分为二,分别进行处理
3. MERGE-SORT (A, p, q) //继续递归看能不能将问题继续一分为二,处理A[p->q]的排序
4. MERGE-SORT (A, q + 1, r) // 继续递归看能不能将问题继续一分为二处理A[q+1->r]的排序
5. MERGE (A, p, q, r) // 合并当前结果
到这里,分治算法的精髓已经出来了,我们通过递归将问题进行分解到足够小…继而进行结果计算…然后再将结果合并.
下面来处理一下边角料的工作,呵呵,让大家看到一个完整的归并排序的例子,整个算法总结系列我都没有很好的使用伪代码,而是使用我认为广泛使用的C语言代码来进行代码诠释.实际上,描述算法最好还是使用伪代码比较好,这里我对我前面的四篇文章没有使用伪代码而小小的鄙视一下自己,太不专业了..呵呵
以下算法MERGE (A, p, q, r )表示合并A[p->q]和A[q+1->r]这两个已经排序好的数组
MERGE (A, p, q, r )
1. n1 ← q − p + 1 //计算A[p->q]的长度
2. n2 ← r − q //计算A[q+1->r]的长度
3. Create arrays L[1 . . n1 + 1] and R[1 . . n2 + 1] //创建两个数组
4. FOR i ← 1 TO n1
5. DO L[i] ← A[p + i − 1]
6. FOR j ← 1 TO n2
7. DO R[j] ← A[q + j ] //4-7行是将原数组中A[p->r]的元素取出到新创建的数组,我们的操作是基于临时数组的操作
8. L[n1 + 1] ← ∞
9. R[n2 + 1] ← ∞ //8-9行设置界限..
10. i ← 1
11. j ← 1
12. FOR k ← p TO r
13. DO IF L[i ] ≤ R[ j]
14. THEN A[k] ← L[i]
15. i ← i + 1
16. ELSE A[k] ← R[j]
17. j ← j + 1 //12-17行进行排序合
这里我还是提供一个具体的实现,请见下面的代码
C语言代码
关于代码注释,请见博客上面的伪代码注释..
void mergeSort(int numbers[],int left, int right)
{
if(left<right)
{
int mid;
mid = (right + left) / 2;
mergeSort(numbers, left, mid);
mergeSort(numbers, mid+1, right);
merge(numbers,left, mid, right);
}
}
int main()
{
int numbers[]={5,2,4,6,1,3,2,6};
mergeSort(numbers,0,7);
for(int i=0;i<8;i++)
printf("%d",numbers[i]);
}
其实本人原来在学习的时候好长一段时间不理解为什么时间复杂度会是O(nlogn),像冒泡排序就比较好理解,有两个for循环,问题的规模随着n变大而变大,算法时间复杂度自然就是O(n*n),后面花了一些时间来阅读一些资料才明白其原理,这里我已经将资料地址放到了本文最后,有兴趣的也可以去看看.简单的描述一下为什么会是O(nlogn)
大家看看,我们的例子,解一个8个元素的数组,我们用到了几层?是四层,假设我们这里有n个元素,我们会用到多少层?根据一定的归纳总结,我们知道我们会用到(lgn)+1层..(lgn)+1层需要用到lgn层次的合并算法.现在再看看MERGE (A, p, q, r )的复杂度是多少,毫无疑问O(n),故其归并排序的算法时间复杂度是O(nlogn).当然这个结果还可以通过其他的方法计算出来,我这里是口语话最简洁的一种..
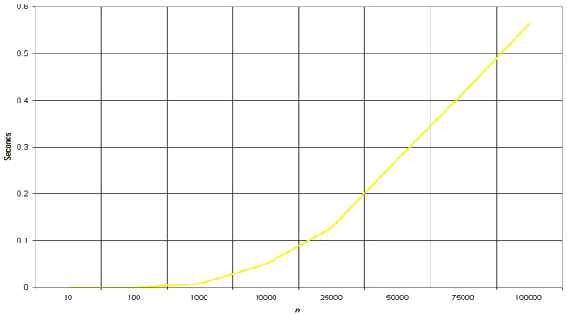
下面来一张算法时间复杂度的与n规模的关系图..